AI在讲图片内容理解之后分层,然后局部去调节人的动作
AI 图像生成的新思路提供了比以往任何AI都多得多的灵活性和控制力。
目前主流的文字描述转图像几乎完全依赖于AI自己生成,人很难去从细节上干涉生成的结果。COMPOSE这个新的AI框架则允许人们去操控生成的细节。
这种突破性的新方法背后的想法是:
1. 将图像分解为一些具有代表性的层,例如文本描述、深度图、样式、语义、色彩等,
2. 然后重新组合这些图层或更改它们以生成新版本的图像。
这样的排列组合为最终的结果提供了近乎无限的可能,为创作者提供了无限的可能。

废话不多说直接来看案例。
通过创建或提取图像的草图层,对其进行更改,然后使用它重新构图。通过创建和更改图像的分割层,更改兔子耳朵的姿态:
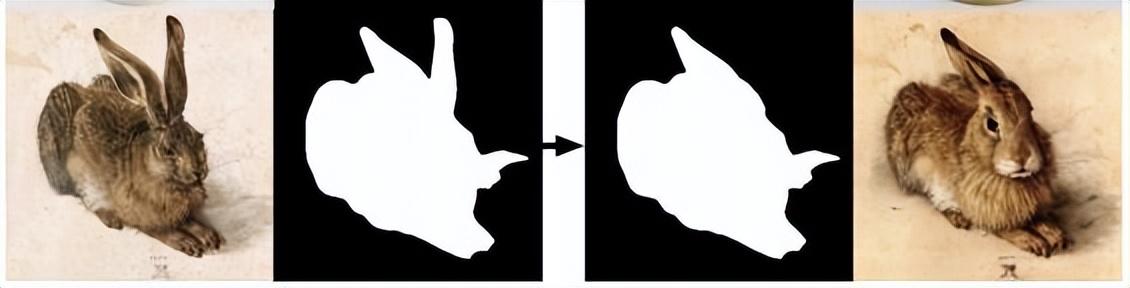
对兔子耳朵这个细节
如果你觉得更改兔耳朵太简单,用PS修一下好像也行,那么继续看下一个案例。
通过一张汽车的照片,生成这款汽车的其它角度的图片。
想要旋转任何给定图像中的单个元素? 没问题,只需要创建一个表示图像旋转的图层。

给图片中的元素进行调色自然也不成问题,,这个案例中给兔子赋予了熊猫配色、汉堡配色等各种各样的配色。

还有下面有趣的这些,自动去掉雪景、更换车的款式、给狐狸披上老虎皮……
配合语音识别完全可以做到用嘴P图,彻底解放双手,最后比拼的就是脑洞。

说到P图,有涂层就离不开遮罩(蒙版)
来看看AI手中图层和蒙版双管齐下会生成什么有意思的作品吧。

甚至还可以给图像添加景深效果(比如这只鹦鹉。)



要实现这些技术上肯定是很复杂的,但是原理却相对比较简单。
跟人工修图的思路差不多,将图片按照对比度、色彩、深度等要素进行解构,再对某一个要素进行修饰或者重构,就可以做到“指哪打哪”对图像的呈现形式进行精准控制。