众多服务同时宕机?!
昨天,OpenAI的ChatGPT遭遇了一次“重大中断”,这导致客户无法与这家超级实验室的聊天机器人进行正常的对话。
问题始于 6 月 4 日 UTC(世界协调时)07:00 左右,截至 UTC 时间 07:21 结束。OpenAI 方面已经承认存在问题并着手开展调查。一个多小时后,OpenAI 宣称已经找到问题所在且正在“处理”。可截至 UTC 时间 10:00,该公司向用户表示“仍在努力解决这个问题”——又一次持续数小时的中断。
问题始于 6 月 4 日 UTC(世界协调时)07:00 左右,截至 UTC 时间 07:21 结束。OpenAI 方面已经承认存在问题并着手开展调查。一个多小时后,OpenAI 宣称已经找到问题所在且正在“处理”。可截至 UTC 时间 10:00,该公司向用户表示“仍在努力解决这个问题”——又一次持续数小时的中断。
在中断期间,ChatGPT的网站曾进行更新,表明服务已经达到最大负荷(显然这是个虚假的说法),并表示将在服务恢复时通知用户。
根据受到影响的用户所说,ChatGPT无法对来自移动端应用或网站的查询做出响应,这可能意味着问题出现在服务器端的某个位置。当我们要求该聊天机器人进行自我诊断时,它简短回应称出现了“内部服务器错误”。
社交媒体上也很快出现了相关内容。一位用户抱怨 ChatGPT反复发生中断和崩溃,表示“真的太烦人了,服务根本无法正常使用。”
另一位用户则评论称,“OpenAI 突然停工导致让很多新手感到焦虑不安了吧,因为他们的工作无法继续进行。”
那些在编程工作中使用聊天机器人建议的开发者,更是首当其冲受到影响。有人评论称,“是谁搞垮了 OpenAI?我还有代码没写完呢。”
不仅仅是 ChatGPT,还有其他系统也在昨天宕机。
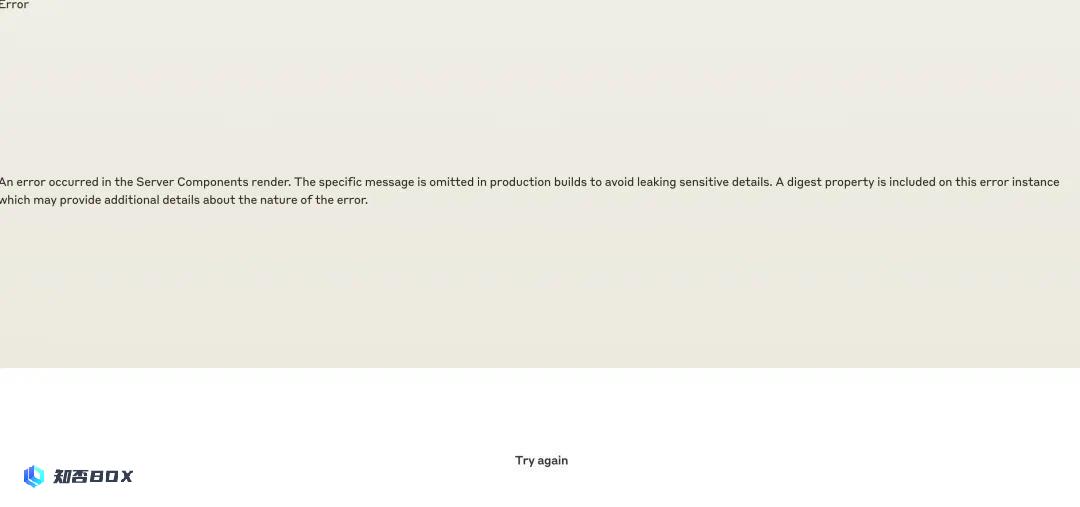
Claude 网站也出现故障,导致用户无法正常访问。网站显示的错误信息为:
服务器组件呈现过程中发生错误。具体错误信息在生产版本中被省略,以避免泄露敏感细节。此错误实例包含了一个摘要属性,该属性可能提供有关错误性质的其他详细信息。
网站建议用户“再次尝试”。
美国东部时间下午 12:10 之后的某个时间,Claude 又开始工作了。
Perplexity 网站也遇到了与 Claude网站类似的超负荷问题,这通常意味着服务收到了过多的请求,导致无法正常响应。网站上显示的消息为:“我们很快就会回来”、“我们现在收到了很多问题,并且已经达到了我们的接待能力。请稍后再试。”
该网站在大约 Claude 网站的宕机问题解决后恢复了正常运行,但此后一直处于间歇性上下线状态。
需要注意的是,根据OpenAI的状态页面显示,截至美国东部时间下午12:28分,ChatGPT仍然无法使用,并且状态被标记为“重大宕机”。
而这段时间,连谷歌的 Gemini 广告平台一样出现了问题。
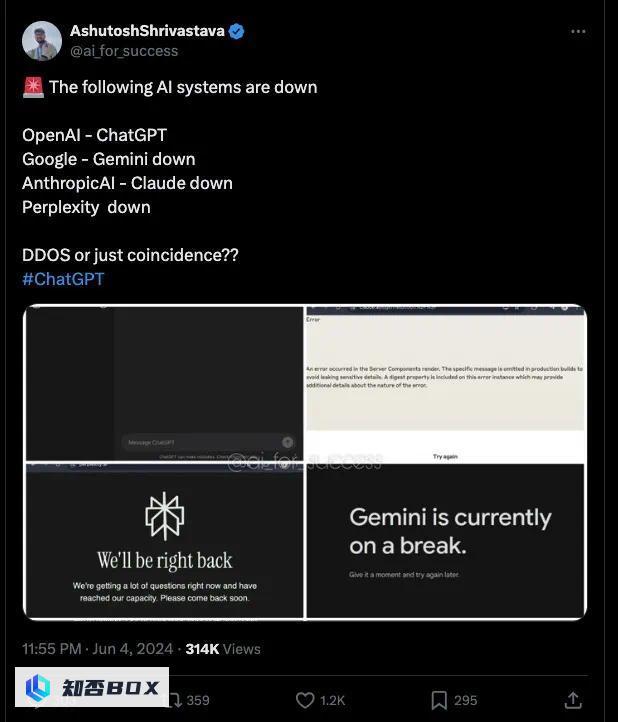
难以解释
ChatGPT最近几个月的表现确实不太可靠,当然这也不能完全归咎于 OpenAI。以 5 月 23 日的事件为例,ChatGPT突然失去了执行网络搜索的能力,这是因为微软 Bing 搜索引擎遭遇了中断,进而对 OpenAI 的服务造成了连带影响。
关于这次宕机原因,据 OpenAI 介绍,他们已经于当天协调世界时17:00解决了宕机问题。OpenAI 方面建议,“对于在 chatgpt.com 上使用 ChatGPT页面的用户,可能需要执行「硬刷新」操作。而对于通过 Mac 应用程序或者我们移动(iOS/Android)应用软件上使用ChatGPT 的朋友,则不会受到影响。”
监测机构 VitoriaMetrics 的联合创始人 Roman Khavronenko 则提问称,“为什么三年之前就在到处宣扬的快速数字化转型,直到今天也无法实现站点的高效规模伸缩?”
监测机构 VitoriaMetrics 的联合创始人 Roman Khavronenko 提出了一个问题,他想知道为什么三年前就开始广泛宣传的快速数字化转型至今仍无法实现站点的高效规模伸缩。“病毒式传播成为新的商业常态,可能够承载病毒式流量的网站则极为稀缺。一旦站点崩溃,企业损失的金钱要比适当投资于基础设施可扩展性与可观察性建设成本高得多。既然大家都说数据是现代企业的命脉,为什么却仍没有得到妥善管理?”
另外,我们知道Anthropic使用亚马逊网络服务(AWS),OpenAI可能使用的是微软或自己搭建的集群,Gemini则使用自家的谷歌云服务。当他们使用不同的服务提供商,同时都宕机,这确实有点说不过去。由于各家都只有道歉没有故障解释,网友们就有了各种分析。
一个有趣的说法是这些服务被启动了“测试模式”。
另一个观点是这些都是GPT的外衣,尽管这听起来很荒谬,但有很多人支持这种观点:

还有一个是美国计算机科学家 James B 的更加正式的分析:

导致同时宕机的可能原因:
基础设施问题: 这些 AI 模型依赖的基础设施出现大范围问题可能是导致问题的主要原因。这可能包括云服务提供商(例如 AWS、谷歌云平台或 Azure)出现故障,而这些服务商正是这些模型运行所依赖的。
互联网层面问题: 另一种可能性是互联网层面出现问题,例如大规模的 DNS 宕机或网络路由问题,这些问题会同时影响多个服务。此类问题会扰乱跨越不同地区连接服务器的稳定性。
因服务器故障导致的高流量: 也不排除最初一个服务(例如 ChatGPT)服务器故障,导致其他服务(Claude AI 和 Perplexity AI)突然流量激增,从而使它们的系统不堪重负并引发后续服务器故障。
以上因素单独出现或混合发生都可能导致观察到的同时宕机事件。
