近日,LeCun和谢赛宁等大佬,共同提出了这一种全新的SOTA MLLM——Cambrian-1。开创了以视觉为中心的方法来设计多模态模型,同时全面开源了模型权重、代码、数据集,以及详细的指令微调和评估方法。
在寒武纪大爆发期间,视觉的出现对于早期动物至关重要。
捕食、避险、引导进化,穿越时间,组成了多彩的世界。

大多数人类知识,也都是通过视觉、听觉、触觉、味觉和嗅觉等感官体验,以及与物理世界的交互所获得。
对应到大模型的学习,虽然更大的规模可以增强多模态的能力,但视觉方面的研究和设计似乎没有跟上。
另一方面,过度依赖语言,则可能会成为多模态学习研究的瓶颈。
近日,LeCun和谢赛宁团队推出了Cambrian-1,一项采用以视觉为中心的方法设计多模态大语言模型(MLLM)的研究,同时全面开源了模型权重、代码、数据集,以及详细的指令微调和评估方法。

整个框架围绕五个关键方面进行构建,同时也代表了作者对多语言大型语言模型(MLLM)设计空间的重要见解:
传统协议与使用MLLM来评估视觉表征的比较:MLM采用视觉问答来解决各种现实世界感知任务。底部突出了Cambrian-1研究的五个关键支柱
Visual Representations:探索了各种视觉编码器及其组合。Connector Design:本文设计了一种全新的动态的空间感知连接器,将多个模型的视觉特征与LLM集成在一起,同时减少了token的数量。Instruction Tuning Data:研究人员从公共来源收集高质量的视觉指令微调数据,同时强调数据的平衡性。Instruction Tuning Recipes:指令微调策略和实践。Benchmarking:分析现有的MLLM基准测试,并引入了一个全新的以视觉为中心的基准测试CV-Bench。
作为这项研究的「附加产物」,团队顺便训练出了一个目前性能最强的多模态模型。(红线是GPT-4V的成绩)
论文的一作Shengbang Tong是马毅教授以前在伯克利带的学生,目前在NYU读博士一年级。
马毅教授表示,这个模型是在过去几个月借谷歌的TPU训练的(等价于1000张A100的算力)。
「所以按照现在技术路线,从头到尾做一个最先进的多模态模型,基本上没有什么学术门槛。适合学AI的研究生热身。」

世界不需要另一个MLLM对打GPT-4V
谢赛宁刚刚发文表示,「世界不需要另一个MLLM与GPT-4V竞争。Cambrian在以视觉为核心的探索是独一无二的,这也是为什么,我认为是时候将重心从扩展大模型转移到增强视觉表征了」。

他继续称,从以往的研究项目(MMVP、V*、VIRL)中,团队已经看到当前MLLM系统在视觉方面存在一些意料之外的缺陷。
虽然可以通过增加数据等方法暂时解决一些问题,但一个根本问题是——我们的视觉表征能力不足以支持模型的语言理解。
短期内,像Astra和GPT-4o这样的项目,确实令人印象深刻。
然而,要开发出一个能像人类一样感知真实世界、可靠地管理复杂任务,并做出相应行动的多模态助手,薄弱的视觉感知基础,可能会成为瓶颈。
语言先验的力量巨大,但我们不应该依赖它们作为“拐杖”来弥补视觉表征的不足。

原始HTML结构内容无法进行合理性扩写,请保留原文:
目前,研究视觉表征学习确实极具挑战性。
虽然基于CLIP模型(由语言强监督)已被证明很有效,但同时也存在一些问题,比如属性绑定。
然而,这些模型已经存在一段时间了,令人惊讶的是我们还没有看到任何重大突破。
尽管如此,我坚信我们应该继续向前推进。
这一情况让人想起2015到2016年,当时大家普遍认为ImageNet监督预训练是无敌的,其他视觉表征至少落后10到15%。
但是,研究人员们并没有被这种情况吓倒,他们依然继续探索各种新的方法和任务。
直到几年后,MoCo就展示了超越监督预训练模型的潜力。
这也是开发Cambrian项目的重要原因——为更多以视觉为中心的探索铺平道路。
之所以将模型称为Cambrian(寒武纪),因为就像寒武纪大爆发时生物发展出更好的视觉能力一样,研究团队相信改进的视觉能力不仅仅是看得更远,而是更深入地理解。
最后的最后,谢赛宁还分享了本人的一些感悟:
当我从业界转到学术界时,我并不确定,我们是否能完成这种需要全栈技能的大型项目。如果没有谷歌TPU研究云计划的支持,这个项目是不可能完成的(非常感谢Jeff Dean和Demis Hassabis对学术界的持续支持)。我认为Cambrian项目证明了学界和业界是可以互补的。
爱丁堡大学机器学习博士Yao Fu表示,作为一个想要了解视觉语言的LLM学者,我发现这篇论文有极高信息量,直接回答了我的困惑。

斯坦福大学博士后研究员Karl Pertsch详细探讨了这项研究的前景,他认为,视觉语言模型(VLMs)在视觉方面仍有许多改进空间,机器人学也可能是一个很好的测试平台!
「对于视觉语言动作(VLA)训练(即视觉语言模型+动作),我们发现现有的视觉编码器需要大量的微调,才能在机器人控制中表现良好,不过在这一领域的评估并不容易。

一起看看这项研究的技术细节。
开始热身
在当前的MLLM研究中,视觉组件的设计选择通常没有得到充分探索,并且与视觉表征学习研究脱节。
这种差距,阻碍了现实场景中准确的感官基础。
这项研究的动机,正是源于当前多模态学习研究存在的两个潜在问题。
1. 过早地依赖语言可能会成为一种捷径,弥补学习有效视觉表征的缺陷
现有的基准可能无法为现实场景提供足够的指导,毕竟,视觉基础对于稳健的多模态理解至关重要。
如上文所言,这些担忧并非空穴来风,因为研究人员已经开始注意到,视觉基础早已成为在具有挑战性的现实世界中应用机器学习语言模型(MLLM)的瓶颈。
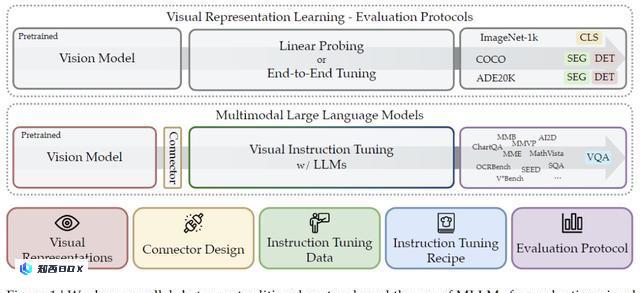
与此同时,用于视觉表征学习的传统评估基准(例如,在ImageNet-1K、COCO和ADE20K等数据集上进行线性探测和端到端微调)正在变得饱和,并不能反映现实世界分布中的多样化感知挑战。
相比之下,使用视觉问答(VQA)形式的语言提供了灵活且强大的评估基准。
而这项研究,就探索了全新的协议基准,从而更好地指导未来的视觉表征开发。

各种视觉模型、目标和架构的示例
多模态领域的基准测试
为了有效评估视觉表征和MLLM,首先就需要选择能够准确评估它们多模态功能的基准。
谁来回答这个问题:LLM还是MLLM?确定基准是否真正需要视觉输入来解决,一直是视觉语言研究中的挑战。
为此目的,研究人员比较了使用23种不同视觉主干进行训练的MLLM,分别禁用和启用它们的视觉能力,并通过随机猜测计算了预期分数。
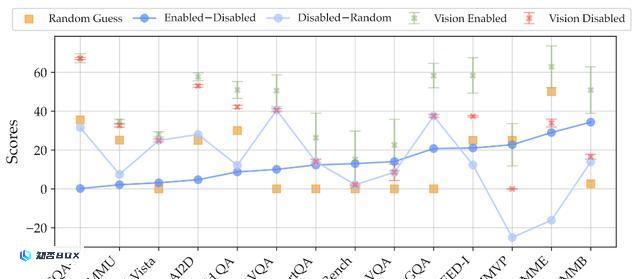
MLLM在启用和禁用视觉输入情况下,在不同基准测试中的表现
实验结果如上图所示,一些基准(比如MMMU和AI2D)不太依赖视觉输入,而在其他基准(如MMVP和MME)上则出现了显著的性能下降,表明后者能够对MLLM进行有效评估。
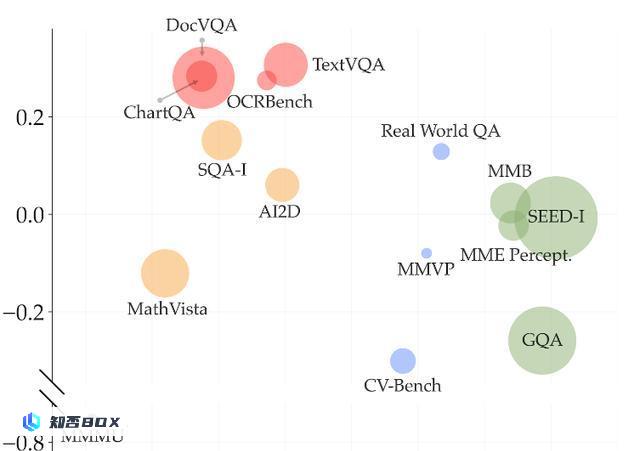
基于性能指标的主成分分析,显示基准测试的聚类情况
通过对各种基准上的MLLM性能的相关性分析和主成分分析,可以得到不同的聚类:蓝色的「通用」、黄色的「知识」、红色的「图表与OCR」和蓝色的「以视觉为中心」。
上图中的圆圈大小表示基准的不同规模,可以看到,以视觉为中心的基准非常稀缺。
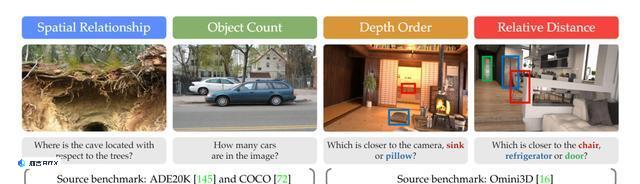
于是,为了更好地评估真实环境中的视觉表征,研究人员通过将传统视觉基准转换为VQA格式,开发了一个以视觉为中心的MLLM基准——CV-Bench。
如下图和下表所示,CV-Bench通过空间关系和物体计数评估2D理解,通过深度顺序和相对距离评估3D理解。

指令微调
一阶段与两阶段训练
MLLM通常使用MLP作为连接器,将预先训练的LLM和视觉骨干网连接在一起。
不过最近的研究建议跳过连接器预训练以降低计算成本(同时不影响性能)。
于是作者用不同大小的适配器数据进行了实验,遵循LLaVA的方法,最初仅微调连接器,然后解冻LLM和连接器。
下图表明,预训练连接器可以提高性能,而使用更多适配器数据可以进一步增强性能,所以这里采用1.2M适配器数据标准化2阶段训练方法。
冻结与解冻视觉编码器
在微调期间可以选择冻结或解冻视觉主干网络。一些人认为,解冻视觉主干会显著降低性能。
本文的实验表明,在合理的视觉模型学习率下,除了知识基准的边际变化之外,解冻有利于提高所有基准测试的性能。
MLLM作为视觉模型评估器
使用2阶段指令微调、1.2M适配器数据、737K微调数据来比较各种视觉模型对下游MLLM性能的影响。
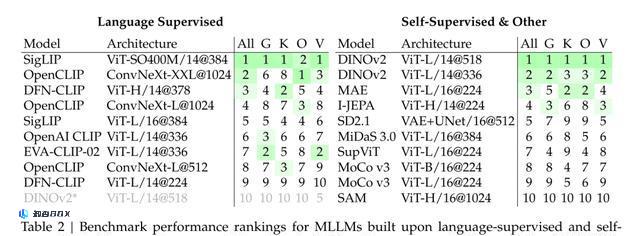
评估结果表明,语言监督模型在所有基准类别中都展示出强大的优势,特别是在OCR和图表任务方面。
另外,尽管DINOv2等SSL模型的数据集较小,但它们在以视觉为中心的基准测试中表现很不错。
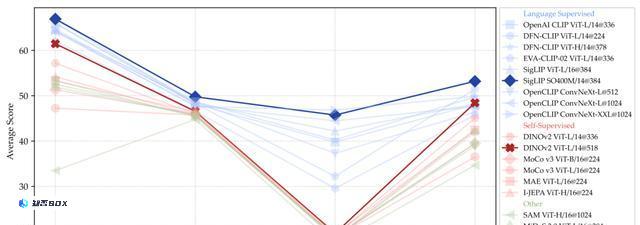
基于语言监督和自监督视觉编码器的多语言学习模型(MLLM)在各类基准测试中的性能排名,包括所有基准测试(All)、一般类(G)、知识类(K)、OCR和图表类(O)、以及以视觉为中心的基准测试(V)。
组合多个视觉编码器
如上图所示,不同的视觉模型在MLLM性能的不同方面表现各有千秋。研究人员于是探索了组合多个视觉编码器以利用其独特的潜力。
鉴于不同的视觉编码器使用不同的架构和图像分辨率,这里将输出视觉标记插值到固定数字576。结果如下表所示,随着更多模型的添加,性能得到了一致的改进。

然而,这种策略有两个局限性:1)采用插值可能会导致信息丢失,特别是在具有高分辨率特征图的视觉编码器上,2)不应简单的串联每个模型,而是需要寻求一种更有效的策略,充分利用模型组合,使信息损失更少,灵活性更大。
缩小CLIP和SSL模型之间的差距
在上面的结果中,DINOv2在一般视觉问答(VQA)和知识驱动问答(Knowledge VQA)任务上,表现处于自监督学习(SSL)模型和CLIP模型之间,而在以视觉为中心的基准测试中优于某些CLIP模型。
研究人员尝试解冻视觉主干并增加视觉微调数据量,以缩小这一差距。
如下图所示,通过解冻视觉主干,并使用5M数据进行微调,基于DINOv2的MLLM超过了使用CLIP模型的MLLM(0.7M训练数据)。

此外,在500万数据的实验设置下,DINOv2与CLIP模型之间的差距缩小了。
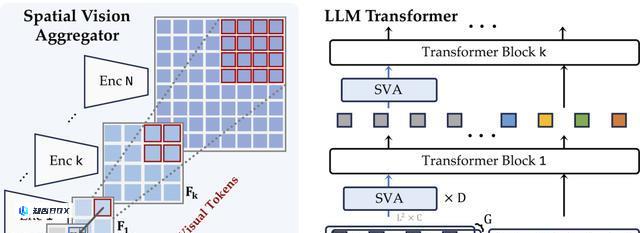
新的连接器设计
为了有效地聚合来自多个视觉编码器的特征并减少插值期间的信息丢失,这里使用一组可学习的潜在查询,它们通过交叉注意力层与多个视觉特征交互。
方法结合了两个新的以视觉为中心的设计原则:
1.通过显式本地化查询中每个标记的聚合空间来编码空间归纳偏差。2.在LLM层中多次执行视觉特征聚合,允许模型重复引用必要的视觉信息。
指令微调数据
研究人员收集了所有可用的指令微调数据,并通过增强多样性、平衡来源和改进混合来检查数据管理。
数据采集
作者首先使用涉及视觉交互数据的现有多模态基准和数据集,例如视觉问答(VQA)和OCR数据。此外还收集了少量高质量的语言指令跟踪数据,以维持其语言能力。

作者还推出了一个数据引擎,帮助创建大规模、可靠、高质量的基于知识的多模态指令微调数据。

最终,这些数据构成了一个大型指令微调数据池——Cambrian-10M,包含大约9784k个数据点。
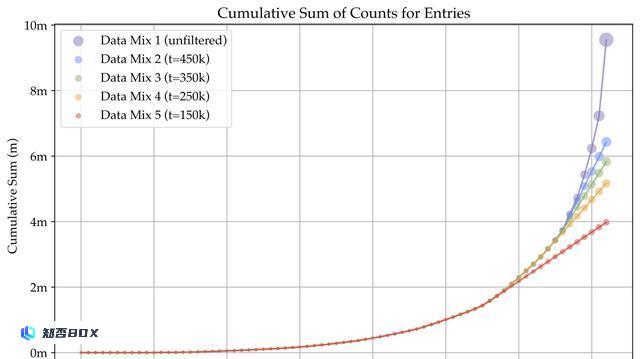
另外,研究人员还通过改进数据平衡和微调数据比率来进行数据管理。
为来自单个数据源的数据点数量设置阈值t,选择t=150k、250k、350k和450k,发现250k和350k之间的阈值对于Cambrian-10M效果最佳。
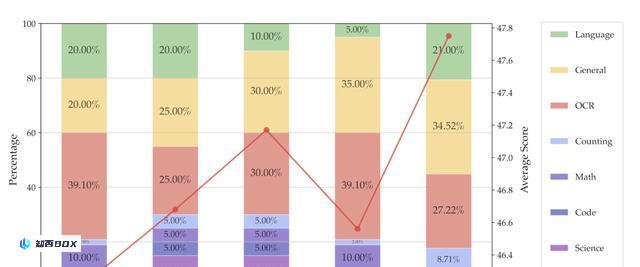
考虑到不同类型的视觉指令微调数据的不同能力,平衡这些数据类型的比例至关重要。
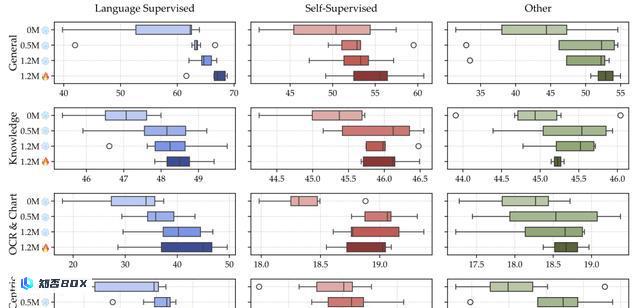
使用1350k的固定数据集大小进行试点实验,检查不同数据比例对下游性能的影响。从下图的结果可以发现:
(1)平衡一般数据、光学字符识别(OCR)和语言数据的重要性不可忽视。
(2)知识密集型任务的表现受到多种因素的影响,通常需要结合OCR、图表、推理和一般感知。
根据您的指示,原始的HTML结构应该保持不变。因此,以下是对字段内容进行合理性扩写后的结果:
答录机现象
如果您希望继续进行内容的扩写或有其他需要,请告诉我。
在这里,研究人员观察到了一种「答录机现象」。
他们发现,训练有素的多模态语言模型(MLLM)在视觉问答(VQA)基准测试中表现出色,却往往缺乏基本的对话能力,倾向于输出简短的响应。
这种差异的原因在于,基准测试问题通常只需要一个选项、选择或单词的回答,这与MLLM在更广泛和现实的应用场景中有所不同。
研究人员认为,这个问题是由于指令微调数据中包含了过多的简答VQA任务,导致大语言模型出现了灾难性遗忘。
作者发现,在训练期间增加额外的系统提示可以减轻这种现象。
通过增加提示,比如“用一个单词或短语回答问题”,模型的基准性能保持不变,但其对话能力显著提升。
比如下图中,带有系统提示的模型会在正确回答问题的同时,产生更长、更有吸引力的回答。
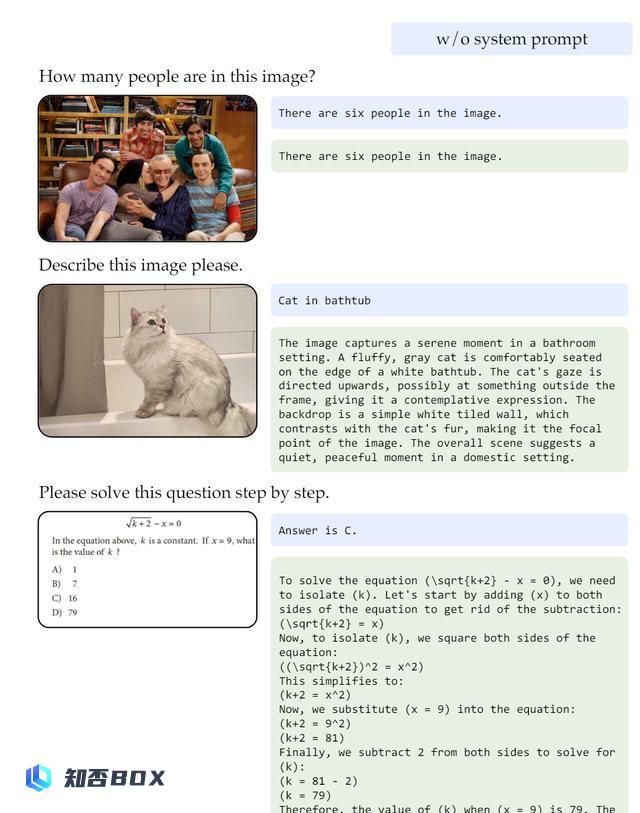
而且,系统提示还会通过鼓励一连串的思考,来增强模型在推理任务(如数学问题)上的表现。

最后,研究人员基于之前的设计框架,训练一个高性能的Cambrian模型。
他们使用了三种参数大小的LLM进行了训练:LLaMA-3-Instruct-8B、Vicuna-1.5-13B、Hermes-2-Yi-34B。
视觉部分结合了四种模型——SigLIP、CLIP、DINOv2和OpenCLIP ConvNeXt,并使用了空间视觉聚合器。
与此同时,训练过程中采用了250万条适配器数据,以及700万条指令微调数据。
经过实验评估,性能结果如下表5所示,Cambrian-1超越了其他开源模型,如LLaVA-NeXT和Mini-Gemini,并在多个基准测试上达到了与最佳专有模型(如GPT-4V、Gemini-Pro和MM-1)相当的性能。
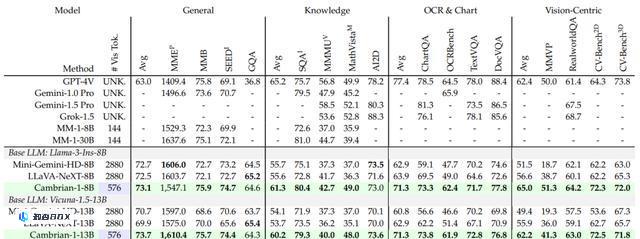
Cambrian-1仅仅使用了576个token,却仍能有效关注图像中的细节。
如下面两张图所示,Cambrian-1-34B在视觉交集方面,展示了令人印象深刻的能力。
从最下面的示例可以看出,它展示出了指令跟随能力,例如json格式的输出。
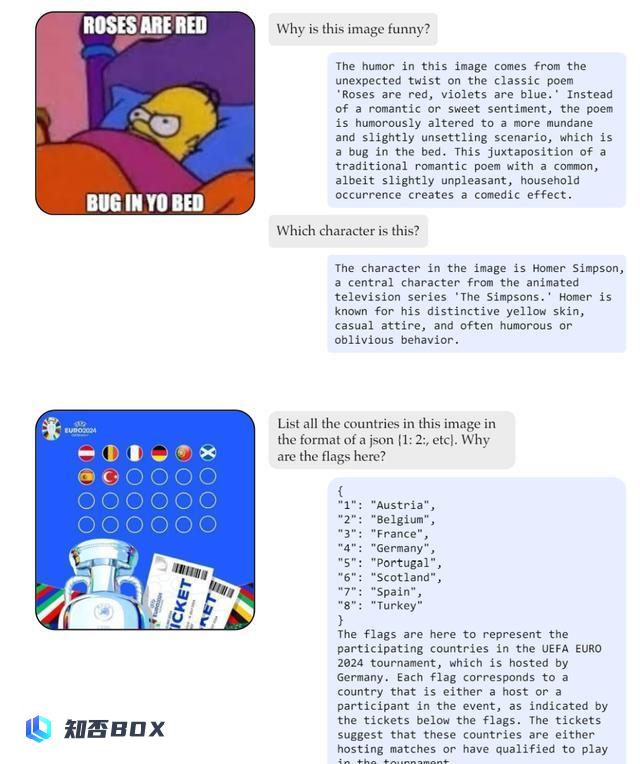
另外,从下图中模型处理不同的逗号的示例可以看出,Cambrian-1还表现出了卓越的OCR能力。

Shengbang Tong

Peter Tong(Shengbang Tong,童晟邦)是纽约大学Courant计算机科学院的一名博士生,他的导师是Yann LeCun教授和谢赛宁教授。
此前,他在加州大学伯克利分校主修计算机科学、应用数学(荣誉)和统计学(荣誉)。
他曾是伯克利人工智能实验室(BAIR)的研究员,师从马毅教授和Jacob Steinhardt教授。他的研究兴趣包括世界模型、无监督/自监督学习、生成模型和多模态模型。
目前,他在纽约大学做研究实习生,导师是谢赛宁教授。

最近,他于卡内基梅隆大学获得硕士学位,导师是Deepak Pathak和Alyosha Efros。在此之前,于范德比尔特大学获得了计算机科学和数学的学士学位,并与Maithilee Kunda一起研究CoCoSci和视觉。
此外,他曾在艾伦人工智能研究所的PRIOR团队进行过实习,导师是Ross Girshick。并且还是BlackRock AI Labs的创始研究工程师,与Mykel Kochenderfer、Stephen Boyd和Trevor Hastie合作进行应用研究与金融研究。
