
由于技术进化放缓,引发了一系列连锁反应。
文丨贺乾明 王与桐 徐煜萌
“Mayday” 可直译为 5 月天,它也是国际通用的无线电求助信号。当飞机有坠落危险时,飞行员会对着对讲机大喊 “Mayday”!
这个五月,可能是ChatGPT发布至今大模型行业最热闹的时候:OpenAI、Google、微软、字节跳动、阿里巴巴等中美两国公司至少举办了 13 场与大模型相关的发布会,介绍了 10 多款新模型,拿出了一堆新产品。
在行业中引起热议的风险和失望主要表现在:许多从业者认为技术没有取得重大进步。
OpenAI 本月新发布的 GPT-40 处理语言的能力停留在 GPT-4水平,被期待已久的 GPT-5 仍未登场。
多模态技术成为顶尖 AI 公司的技术焦点:从 OpenAI、Google 到微软,发布能同时处理语音、图像,甚至理解现实世界的模型。但这些能力支持的产品和应用都还在 Demo 阶段,没正式发布就引出了侵权、隐私隐患等各种麻烦。
唱衰大型模型创业机会的金沙江创投主管合伙人朱啸虎有一个观点:如果语言能力的进化速度变慢,“这股热潮就将告一段落了”。
“没有什么令人兴奋的。” 一位在中国大公司带队研发大模型的专业人士表示,一系列发布会让他更相信,开发能力更强的小模型才是未来。
一位人工智能创业者表示,GPT-4o并非颠覆性技术,对通用人工智能(AGI)并无帮助,但它基于一些顶级单点技术构建了组合式创新,提升了交互能力,有助于普及应用。
除了技术竞争外,大家更关注的是大型模型的价格战。在5月份的发布会上,OpenAI和Google都宣布将核心模型的价格降低50%。
在中国,量化交易公司幻方在5月初降低了超过90%的模型价格;大型人工智能公司智谱AI紧随其后。随后的两周,字节跳动、阿里巴巴、百度和腾讯等大公司也纷纷降价甚至提供免费服务。
一家中国大型企业的代表在本月的座谈会上表示:“如果降价策略演变成了烧钱行为,演变成了社区团购,就不利于技术的发展。” 他们自己也参与了降价活动。
关于如何监管大型模型的争论也在这个月达到新的高潮。
美国和欧洲政府都选择加强监管。美国国会开始考虑提出限制出口开源大模型的法案;欧盟在5月中旬正式批准起草了为期3年的《欧盟人工智能法案》。
OpenAI 首席科学家伊利亚·苏茨克维(Ilya Sutskever)和旨在确保 AI 安全的超级对齐团队负责人扬·莱克(Jan Leike)等数名人员在 5 月离职。莱克在社交媒体上指责 OpenAI 不重视 AI 安全,他们团队分得的资源严重不足:“我们迫切需要弄清楚如何控制比我们聪明得多的人工智能系统。”
图灵奖得主杨立昆(Yann LeCun)针锋相对地评论:在控制人工智能之前,“我们先要找到一点能设计比家猫更聪明的系统的迹象”。他认为大规模模型远不如一些人所描绘的强大。
一批受限于资金压力、技术进步和变现困难的大型知名创业公司在5月集体寻求出售,例如专注于开发AI智能助手的明星公司Adept,参与开发了文生图开源模型Stable Diffusion的Stability AI以及开发了AI智能销售助手的硬件公司Humane等。
“在推广高科技产品的过程中,最危险的时刻往往是从早期市场过渡到主流市场的阶段。” 美国组织理论家杰弗里·摩尔(Geoffrey Moore)在《跨越鸿沟》一书中指出,这个阶段存在着经常被人忽视的鸿沟。
最初采用新技术的群体的观点和需求并不一定代表主流群体,甚至可能会误导新产品开发公司,使他们误以为已经触及了主流人群。摩尔认为,只有成功地跨越这一障碍,新技术才能创造财富,否则将会失败。
大型机器学习模型正在逐渐接近技术发展的边缘。全球最知名的人工智能产品ChatGPT 的日活跃用户已经达到数千万。早期尝试使用的用户之后,所有公司都迫切希望吸引大量用户群体。
热闹的五月,放缓的模型进展
相比 ChatGPT、GPT-4、Sora 发布时引发的全球震动,OpenAI 在 5 月 13 日推出的 GPT-4o 更像是给过去一年多大语言模型的性能狂飙点了一脚刹车。
据 OpenAI 公布的评测数据,他们投入数百人研发的 GPT-4o 相比之前的 GPT-4 Turbo ,文本处理能力提升不大:MMLU(本科生水平的知识)得分提升 2.5%、HumanEval(编程能力)提升 3.6%、MGSM(跨语言数学能力)提升 2.3%、DROP还下降了 3%。
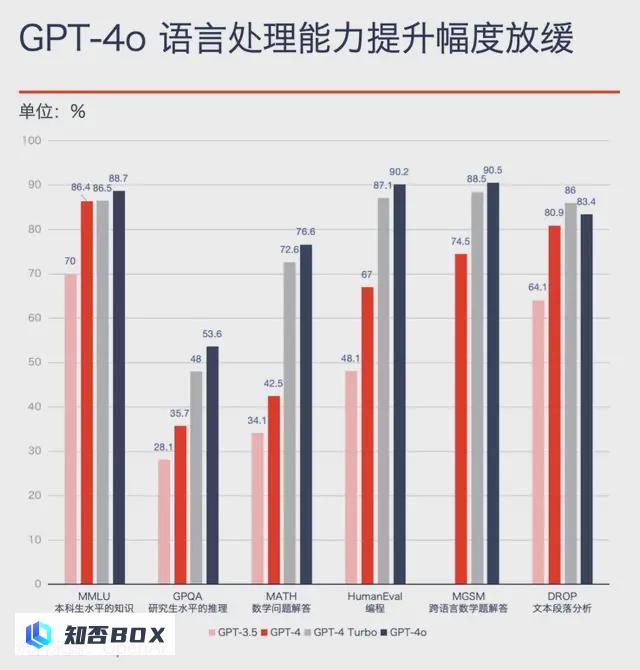
“这个趋势很可能会持续下去。” 中国国内的大型模型独角兽 MiniMax 的天使轮投资人、云启资本合伙人陈昱表示,一个关键原因是能够训练大型语言模型所需的优质数据已接近耗尽。
GPT-4o 的提升主要在文本之外的语音、图像等多模态功能上,其中最受关注的是语音能力,它用上了端到端架构——输入端是语音,输出端也是语音,不需要在中间用文本做转换。
端到端的最大提升是将语音对话产品的响应时间从数秒减少到数百毫秒,延时低到人耳无法察觉的程度。这也使得用户能够随时打断机器人,在对话中更符合人与人聊天时的习惯,而不是一问一答的模式。
一位中国大型独角兽创始人表示,OpenAI 最强的地方在于,尽管它不一定是第一个发明某种技术的公司,但总能够在优化方面做到最好。例如,杨立昆领导的 Meta AI 实验室几年前就开发了语音端到端模型,但效果一直不如传统的语音转文字再转语音。他说:“OpenAI 在这个工程问题上的解决方式令人印象深刻。”
另一位考虑开发端到端语音模型的创始人认为,语音可以被视为语言的外在表达,OpenAI 已经证明了这一技术在提升产品体验方面是可行的。
然而,OpenAI目前尚未向用户开放端到端语音对话功能,他们表示“仍有一系列问题需要解决”,预计语音和视频功能将在几周后上线。
另一个可能被忽视的进步是 GPT-4o 的图像生成能力。在能力评测数据集上,GPT-4o 的图片理解能力得分相比 GPT-4 Turbo 和同行们的 Gemini Ultra、ClaudeOpus 有大幅提升。一些从业者认为,部分指标几乎相当于 GPT-3.5 到 GPT-4 的变化。
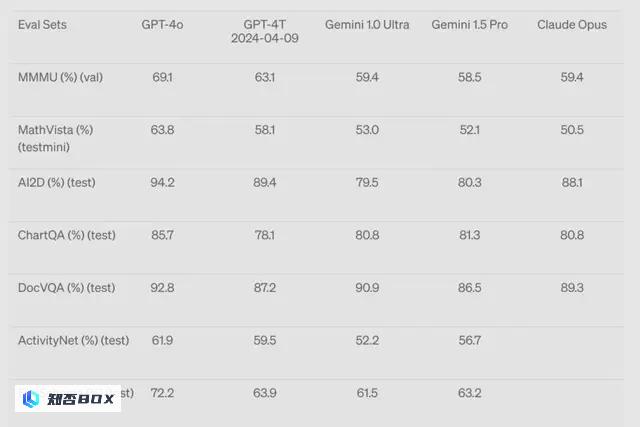
OpenAI 发布会没有展现的一点是,GPT-4o 现在已可以生成图片中的文字。之前,让大模型生成出正常的文字,难度不亚于让模型生成正常的人手,现在也没几个模型能做到。
Google 5 月 14 日的 I/O 大会甚至没提太多大模型处理文本能力的新进展。能处理图像、语音的模型 Project Astra 和 Gemini 1.5 Flash 成为重点。
Astra 通过摄像头识别现实环境、解读代码,进行数学计算,并且能够几乎实时地与人进行语音交互。Gemini 1.5 Flash 是一款规模更小的模型,Google 没有公布它的具体参数,只强调它可以发挥不输更大参数模型的能力:能够高效处理文本、图像和视频数据。
6 天后的微软 Build 大会上,OpenAI 不再像一年前那样是唯一的大模型主角。除了介绍多个公司的大模型,微软还发布了只有 42 亿参数的自研模型 Phi-3-Vision。这也是一个能理解图像和文字等多种模态信息的模型。而且因为参数足够小,它可以被应用到移动设备中。
OpenAI、Google 和微软发布会上展现出的技术趋势,是当前大模型发展的缩影:文本处理能力进步放缓;处理语音、图像的多模态能力成为重点;开发参数更小但性能更强的模型。
它们共同致力于实现同一个目标:以更低的成本、更丰富的功能,推动大型模型进入更多商业场景,让更多人频繁使用。
已经过去一年多了,但我仍在不断寻找那些能够改变游戏规则的顶级应用。
想要实现让更多人频繁使用产品的目标,仅仅依靠技术是不够的。OpenAI CEO 山姆·阿尔特曼(Sam Altman) 在微软的发布会上表示:“AI 并不意味着可以轻松开发一个伟大的产品、公司或服务,只靠 AI 无法打破一些商业规则。”
OpenAI凭借着更强大的模型和先发优势,去年通过会员销售实现了超过10亿美元的收入,显然与他们过去和未来的投入需求不成比例。
据美国红杉资本估算,大规模模型行业购买英伟达的图形处理器(GPU)就投入了500亿美元,而收入仅为30亿美元。与过去的互联网、移动互联网、云计算技术变革相比,大规模模型的商业化进展相对较弱。苹果推出App Store两年后,Instagram就出现了。
即使如此,微软、Google、Meta 等公司今年仍计划投入数百亿美元购买英伟达的 GPU,用于训练更强大的大型模型,为未来可能出现的大型模型应用爆发做好准备。
它们设想中的爆发方向包括语音助手、搜索引擎、操作系统等。这些产品在五月的发布会中频繁亮相。
据市场消息,据市场消息,苹果已与 OpenAI 签订协议,用 GPT-4o 的语音处理能力改进 Siri,将在下个月的 WWDC(苹果全球开发者大会) 上宣布。一同被苹果考虑的还有 Google、Anthropic 开发的模型。
除了手机,耳机也成为硬件焦点之一。OpenAI 发布会之后,据报道,字节跳动花费了5000万美元收购了一家耳机公司,预计字节跳动可能会将大型人工智能模型与耳机进行结合。
“GPT-4o 让我们看到了语音交互效果提升后的情况。” 近期投资了另一家国内智能耳机创业公司的投资人说,当前市场上的 AI 硬件都不算成功,很大原因在于它们与手机的重复度太高,“它们能做的,手机上也可以,但大多数人都需要一个单独的耳机。”
微软设想的一个杀手级产品是植根于 Windows 11 操作系统中的 Recall 功能。它可以 “记住” 用户过去 3 个月内在设备上使用过的应用程序,处理过的文件内容等信息。用户只需要一句话就可以搜索到自己处理过的信息。
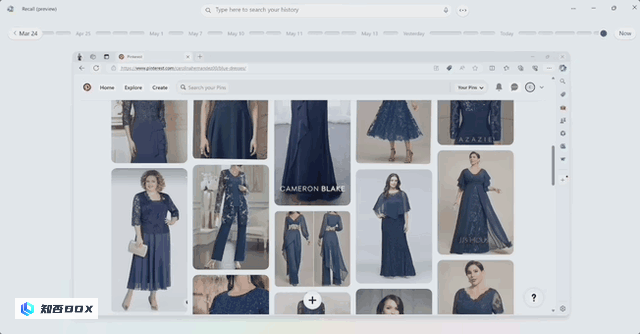
在上方文本框输入 “蓝色连衣裙 ” 后,Recall 功能可以搜出来用户在电脑上看过和输入过的相关信息。图片来自微软。
Google 最近将大型模型与搜索引擎相结合,推出了名为 AI Overviews 的新功能。当用户进行搜索时,这一大型模型会分解问题,然后搜索各种网页,自动生成可用的答案,并提供相关链接。
然而,这些产品在证明能够吸引更多大众用户之前,都遇到了一些挑战。
OpenAI 的 4o 语音功能因使用了一款与科幻电影《她》(Her)的配音者、演员斯嘉丽·约翰逊非常相似的声音,被她本人抗议。这款声音已下架。
微软的 Recall 功能需要定期自动截屏,以记录设备上的各项操作。这种方法经常被一些互联网公司用来监控员工,现在却成了使用新鲜大模型功能的前提。尽管微软强调数据会被加密存储在设备上,但仍然引起了隐私风波。
Google 的 AI Overviews 更是会输出匪夷所思的结果:建议苦恼披萨上的奶酪总是掉下来的用户在披萨上涂胶水;告诉用户过去 20 年美元的通胀率是-43.49%(实际为 77%);人眼可以直视太阳 15 分钟。
至于 OpenAI 的 GPT-4o 和 Google Astra 虚拟助手展现的大模型理解图片、视频和现实世界的能力,则还需要找到具体产品形态和应用场景。一位中国大模型独角兽公司创始人说 “如果模型只是看到三个人在喝咖啡,没有什么商业价值。如果没有应用,模型又怎么持续优化?” 把多模态模型用到机器人身上(具身智能)可能是一个有价值的方向,但想要做好太难。
“跨越鸿沟的基本原则,是找准一个具体的细分市场作为攻击点,集中所有资源全力进攻,以最快的速度拿下领导地位。” 杰弗里·摩尔在《跨越鸿沟》一书中写道。现在大型公司仍在努力寻找:这个确切的攻击点究竟在哪里呢?
降价不仅仅是由技术优化带来的,也源自于敢于亏钱
价格战是5月的另一个人工智能主题。
发布 GPT-4o 时,OpenAI 宣布调用 GPT-4o 模型 API (编程接口)的价格比 GPT-4Turbo 下降一半,处理 100 万 Token 的输入只用 5 美元。Google 也跟着把其主力模型 Gemini 1.5 Pro 的调用价格调低了一半,处理 100 万 Token 只要 3.5 美元。
但与中国大型公司不惜降价超过90%的激烈竞争相比,它们只打五折的降价幅度还是太小。
5 月 7 日,量化交易公司幻方发布了新的模型 DeepSeek-V2,该模型被定位为对标 GPT-4,但其 API 价格仅为 GPT-4 Turbo 的近百分之一:处理 100 万 Tokens 输入 1 元人民币,输出 2 元(32K 上下文)。
5 月 11 日,国内领先的大型创业公司智谱 AI 宣布降价,旗下入门级产品 GLM-3 Turbo 模型的调用价格从每百万 Tokens 5 元降至 1 元。
5 月 15 日,字节的豆包大模型正式上线,开始向外提供服务。该模型将处理输入文本的价格定在 0.8 元 / 百万 Tokens,也就是说处理 1500 多个汉字只需 8 厘钱,宣称比行业水平便宜了 99.3%。
一周后的五月二十一日,阿里巴巴进一步降低了对标GPT-4的Qwen-Long API的价格,降至0.5元/百万Tokens。
当天下午,百度宣布他们的主力模型文心一言 ERNIE Speed 和 Lite 模型将免费提供。
第二天,腾讯宣布推出轻量化的大型模型“混元-lite”,并宣布免费提供。同时,最高配置的万亿参数模型“混元-pro”价格降至每百万 Tokens 300 元,降幅达到了70%。
一些公司正在努力降低最高端模型的价格,比如阿里、字节跳动和幻方;而百度、腾讯和智谱则主要专注于降低更轻量、更小的模型的价格或提供免费服务。
低价和免费服务也受到一定的限制条件。当企业或开发者真正开始调用模型来开发产品时,如果想要提高调用大模型处理文本的频率或者处理更多文本,就需要额外花费。
阿里通义大模型降价的那个上午,我们正在采访使用阿里通义大模型做儿童绘本的创业公司童语故事。被问及豆包降价后是否会考虑切换,童语创始人张华说:“如果只考虑降价,那么阿里肯定也会降,所以不用换。”
不到一小时后,交谈还未结束,张华的手机上就弹出了一条新闻:阿里通义也降价了。
降价部分来自技术优化。字节跳动旗下火山引擎总裁谭待在 5 月发布模型和宣布降价的发布会上说,他们有多个降价技巧,如调整模型架构、把在单个设备上做推理改成在多个设备上分布式推理,集中处理模型调用任务,提升芯片的利用率。
整个大模型行业的降本共识还有:利用更多高质量数据来训练规模较小的模型,参数较少的模型推理成本较低;训练MoE架构的大模型,在处理文本时不需要运行所有参数,从而节省算力。
芯片在降价中扮演着重要角色。英伟达公司在年初宣称,通过改进推理框架等方法,他们成功将大型模型的推理成本在一年内降低到了原本的四分之一。而今年3月,英伟达发布了新产品GB200,声称它能够再次将大型模型的推理性能提高30倍。
中国大型企业预计将继续实施降价策略。它们同时涉足云计算和大型模型,降价的商业合理性可以通过模型作为云服务的引子来实现,例如存储和数据库等。
一位云计算厂商代表表示,与其降低价格,GPU 空置才是云厂商更大的成本:“一套 8 块的英伟达高端 GPU 服务器,现在一个月租金要大几万,如果卡买得多,租不出去、空置才是亏钱。”
据他推测,阿里通义降价后仍然能够获得利润:“现在训练模型的需求减少了,空闲的高端 GPU 可以用于推理,从理论上来说,综合成本是一样的,因为资源已经虚拟化了。” 中国体量最大、机房最多的阿里云具有成本优势。另一位阿里云员工也表示,阿里云大模型降价后并不亏钱;降价也不是为了对抗价格战,而是既定战略。
创业公司则持观望态度。百川智能创始人王小川在5月下旬的一场媒体沟通会上多次被问及怎么看大公司的大模型价格战。“你们去问他们,我们有自己的节奏。” 王小川说,百川不会加入价格战,他认为降价的云厂商卖的不是模型本身,而是背后的整套云服务,与大模型创业公司的逻辑不同。
零一万物创始人李开复也在五月下旬的分享会上表示不愿参与价格战:“如果中国市场竞争如此激烈,大家宁可赔本、互相压价也不让对方获利,那我们就转向国外市场。”
云启资本陈昱对比了过去的打车和 O2O 大战,当时创业公司激进价格战的逻辑是通过不断烧钱来击败竞争对手,最终实现垄断。然而,大规模的模式并不需要耗费大量精力进行地推和扫街,而大公司很容易陷入困境。
“创业公司能够投入的资金是有限的,即使获得了 10 亿美元的融资,大公司单个季度的利润也远远超过这个数字。” 他认为价格战最终还是大公司获胜,“除非创业公司另辟蹊径,走上与大公司不同的产品和商业化路线。”
再小的模型都需要推理成本。现在百度、腾讯等公司对部分模型已经实现了免费使用,字节跟进的降价幅度也超出了一般的降本速度。这种 to B 销售大模型 API 的竞争也带动了前期亏损换取用户的 to C 产品竞争。
资金不足,一些大型企业正寻求退出市场
在新模型和新产品不断发布、价格战愈演愈烈的情况下,一大批明星人工智能创业公司正在陆续退出市场。
今年 5 月,Transformer 作者之一参与创办的 Adept 被报道考虑出售,已接触了 Meta;参与开发开源文生图模型 Stable Diffusion 的公司 Stability AI 去年就在寻求出售,现在仍在与不同买家接触;大模型开发商 Reka 正在以 10 亿美元估值寻求被收购;AIPin 背后的 Humane 也正以 7.5 到 10 亿美元的价格寻找买家。
在中国,一些立志追赶 OpenAI 的大模型公司已经相当长一段时间没有获得新的融资。还有一些公司迅速调整方向,比如面壁智能现在正在研发能够在手机等终端上使用的小型语言模型,今年 4 月完成了由华为旗下哈波基金领投的一轮数亿元新融资。
截至今年5月,中国顶尖大型企业的单笔融资额已达数亿美元,能够获得新融资的公司数量逐渐减少;而有能力支持大型企业后续融资的投资方也越来越集中于大型互联网科技公司。
一位小型投资机构的投资人表示:我们已经没有机会投资那些规模达到十亿元的公司了。在某次会见大型创业公司时,他提出想要一些投资额度,但对方没有给予:“我反而松了一口气,因为我知道我们负担不起。”
大型应用程序领域仍然涌现出新的公司和新的交易。美国红杉资本合伙人索尼娅·黄(Sonya Huang)认为,目前还没有任何大型应用程序的用户留存率达到流行移动应用的水平,因此对于大型应用程序的创业者来说,窗口期仍然存在。
据了解,去年曾被认为将被大语言模型取代的秘塔,在今年 3 月推出秘塔搜索并取得了超过500%的用户增长后,多个互联网大公司向它抛来投资橄榄枝。曾做出妙鸭相机的张月光,在新创业方向尚未明朗时,就已获得了近3亿元人民币的融资。
模型层的价格竞争客观上降低了一些想要基于大型模型进行应用开发的新玩家的试错成本。整个5月,快手、网易、字节跳动相继有人工智能产品或技术负责人离职,投身创业。比如网易副总裁兼研究院院长汪源在社交媒体上公开宣布,将回到To C市场,招募具有海外人工智能或生产力工具类软件方面经验的产品、运营、算法和应用开发人才。
应用公司获得初始融资的门槛不如大型公司高,但竞争难度不小于资源集中的模型层。
“出来得太晚了。”一位投资人评价 5 月密集的创业新动向:“更重要的是,他们能有什么新想法呢?现在硅谷普遍的反馈就是,受限于大模型能力进展,这半年没有新东西出来。”市场上仍能看到早期投融资交易的原因是:“第一轮的资金容易获得,大家缺乏资产,总想冒一下险。但后面就得看产品数据了。”
据安永(爱尔兰)在5月中旬的预测,全球范围内对人工智能的投资正在下降。预计今年全球风投投资人工智能将达到120亿美元,而已经过去的一季度这个数字为30亿美元。预计到2023年全年的总投资额将达到213亿美元。
那些正寻求出售的大模型公司,现在更难找到合适的买家。去年市场上还有 Datebricks 以 13 亿美元收购 MosaicML。而新近寻求收购的一批 AI 公司的潜在买家往往都已建立了自己的 AI 团队,或此前已收购了一些公司。
据 The Information 报道,接近 Snowflake 的人士透露,Reka 和 Snowflake 间的收购谈判已破裂;接近 Meta 的人士也称,Meta 不太可能收购 Adept。
进入场地时需要抓住合适的时机,离开时也是如此。
尚未实现繁荣就受到监管,如何预防大型模型的争议仍在持续
围绕当前的人工智能是否已经变得强大到需要被限制的争论也在这个月进一步加剧。
5 月 20 日,25 位科学家在《科学》(Science)的政策栏目上发布了一篇题为《在人工智能飞速发展进程中管理极端风险》(Managing extreme AI risks amid rapid progress)的文章,署名作者包括约书亚·本吉奥(Yoshua Bengio)、杰弗里·辛顿(Geoffrey Hinton)和姚期智(Andrew Yao)三位图灵奖得主。
这些科学家认为 “缺乏准备的代价远远大于过早准备的代价”,呼吁各国政府更有力地规范人工智能,并警告 “近六个月所取得的进展还不够”。
另一位图灵奖得主、Meta AI 首席科学家杨立昆认为这种观点荒谬可笑。两派观点的核心分歧是,AI 到底有多强?
写联名信的科学家看到,人工智能(AI)已经在玩策略游戏和预测蛋白质结构上超过了人类,它还能复制数百万个自己:“在这个十年或下个十年内,将开发出在许多关键领域超越人类能力的高度强大的人工通用智能(AGI)系统。那时会发生什么?”
杨立昆则认为家猫都比现在最优秀的大模型聪明,大模型并不能真正理解逻辑和做因果推理,现在就急迫地讨论 AI 的安全性,就好像有人在 1925 年说:“我们迫切需要弄清楚如何控制能够以接近音速运送数百名乘客的飞机。”
人工智能科学家李飞飞和斯坦福人工智能研究所的联合主任约翰·艾克曼迪(John Etchemendy)也在五月下旬于《时代》杂志发表文章称,大模型 “只是在概率性地完成任务而已”。
政府宁可未雨绸缪。2021 年 4 月,欧盟委员会就提出人工智能法案草案,以 “风险为本”(risk-based approach)的方式,从政府层面规制 “人工智能的应用边界” —— 尽管他们尚不知道边界在哪。
该草案提出两年内都没有太大进展。直到去年 ChatGPT 席卷全球,该草案增加了大模型监管内容,并于去年被正式投票通过。
今年 5 月,欧盟理事会正式批准该法案生效。法案要求在欧盟提供服务的大型公司披露训练模型时使用了哪些有版权的数据,以及哪些内容是由人工智能生成的。此外,还要求防止模型生成有害内容。
去年,美国政府通过了关于人工智能监管的法令,而在本月又推出了一项新的法案。与之前强调规避大型模型对“国家安全、国家经济安全等构成严重风险”不同,这项新法案是2018年《出口管制改革法案》的修订版,其核心目标是方便限制开源模型的出口,以“保护美国人工智能及其他支持技术免受外国对手的利用。”
该法案于5月23日通过了众议院外交事务委员会的投票,接下来的立法流程包括:众议院和参议院的投票以及总统的签署。
如果说各国政府对互联网的监管和反垄断是后知后觉,对 AI 的提防则来得早得多。这是一个还未进入商业应用大繁荣就被监管的行业。
OpenAI、Google、Anthropic 等大型模型领先者和大公司倾向于推动监管。在过去的一年里,多封强调大型模型风险的公开信中都提到了这几家公司的高层人员。更严格的监管对于领先者有利,但对于资源有限的中小公司和非主流方向的探索与创新则不利。
然而,与公司之间的竞争相比,当前整个大型模型领域更需要新的技术“刺激剂”,要么更快地摆脱黑科技的光环,开始实际应用并盈利。
去年五月,借着 GPT-4 刚刚发布引发的关注,山姆·阿尔特曼开始了全球旅行,与多个国家的政要交流关于如何监管大型模型的问题。
一年过去了,OpenAI的安全团队负责人已经离职。阿尔特曼也不再关注大型模型的风险,而是更多地参加各种活动,宣扬即将推出的更强大的GPT-5。
题图来源:pixabay
