近日,经过众多人的期待,Meta公司终于发布了开源大模型Llama 3的8B和70B版本,这一消息再次引起了人工智能领域的轰动。
Meta 表示,Llama 3 已经在多种行业基准测试上展现了最先进的性能,提供了包括改进的推理能力在内的新功能,是目前市场上最好的开源大模型。
Meta 表示,Llama 3 已经在多种行业基准测试上展现了最先进的性能,提供了包括改进的推理能力在内的新功能,是目前市场上最好的开源大模型。根据Meta进行的测试结果显示,Llama 3 8B模型在语言理解能力(MMLU)、通用问题回答能力(GPQA)、编程能力(HumanEval)等多个性能基准上都超过了Gemma 7B和Mistral 7B Instruct模型。而70B模型则在性能上超越了闭源模型Claude3的中间版本Sonnet,并且与谷歌的Gemini Pro 1.5模型相比取得了三胜两负的成绩。此外,Meta还透露,Llama 3的400B+模型目前仍在训练中。

Meta 在开源大模型领域保持了其领先地位。
开源 Llama 3 的发布对整个大模型行业都是具有重大影响的事件,再次引发了对“开源与闭源之争”的激烈讨论。然而,在国内的情况却截然不同,出现了一种不太令人愉快的声音在网络上扩散——“Llama 3 发布,国内大模型又有了新的突破机会”。
甚至在 Llama 3 还未发布时,就能听到人们说“如果国内想要超越GPT-4,就得等待Llama 3的开源发布”。
开源本身是一项旨在打破技术垄断、促进整个行业不断进步和带来创新的事业。然而,每当Meta发布新的开源项目,从Llama到Llama 3,国内的大型模型都不可避免地遭受到国内用户的嘲笑和贬低。
其实不仅仅是大模型,从云计算到自动驾驶,类似的说法一直存在,这是因为长期以来中国的技术发展一直落后于国外,这种情况导致了国内技术的不自信。即使在某些领域取得了领先地位,也会遭到不信任和质疑的声音。
然而,经过一年的努力和积累,像Llama这样的国外大模型一直表现出色。与此同时,国产大模型也逐渐崭露头角,变得越来越强大。甚至在Llama 3发布之前,国产大模型已经达到了Llama 3的效果,甚至更加强大。
最近,清华大学 SuperBench 团队在不久前发布的《SuperBench大模型综合能力评测报告》的基础上,对 Llama 3 新发布的两个模型进行了额外测试。他们测试了 Llama 3 在语义(ExtremeGLUE)、代码(NaturalCodeBench)、对齐(AlignBench)、智能体(AgentBench)和安全(SafetyBench)五个评测集中的表现。
SuperBench 团队共选取了如下列表模型,将Llama 3 放置到全球内的大模型行列中进行对比,除了国外主流的开源和闭源模型,也将 Llama 3 跟国内的主流模型进行对比。
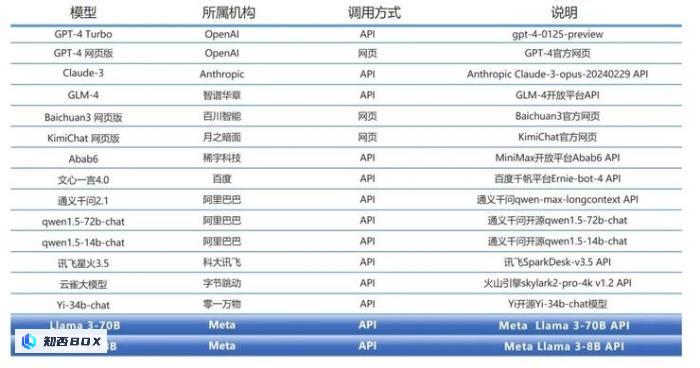
对于闭源模型,SuperBench 团队选择了API和网页两种调用模式中得分较高的一种进行评测。
根据他们发布的测评结果,可以得出以下结论:
(1)Llama 3-70B 版本在各个评测集上的表现都不如GPT-4系列模型和Claude-3 Opus等国际一流模型。在语义和代码两项评测中,与榜首的模型相比,差距最大。然而,在智能体评测中,Llama 3-70B表现得最好,排名第5。需要注意的是,考虑到模型参数量的差异,Llama 3-70B整体表现还是不错的。
(2)和国内其他大型模型进行对比,Llama 3-70B 在五项评测中表现出色,超过了大部分国内模型,只在GLM-4和文心一言面前稍显逊色。
根据 SuperBench 标准测试结果可以发现,国产大模型早已有能力超过 Llama 3 的大模型,国产大模型 GLM-4 和文心一言早就达到了 Llama 3 的实力水平,属于全球大模型竞争的顶尖阵营。经过一年的追赶,国产大模型与GPT-4 之间的差距正在逐渐缩小。
而这也让一些人对于“Llama 3 发布,国内大模型又能有新突破了”“国内要想赶超GPT-4,就等着 Llama 3 开源吧”的技术不自信的论调感到怀疑,认为这种观点不成立。
1 GLM-4 是一种超过Llama 3-70B的产品,它具有更高的性能和功能。
SuperBench大模型综合能力评测框架,是由清华大学基础模型研究中心和中关村实验室于2023年12月共同发布的。该框架的研发背景是基于过去一年里大模型领域的评测乱象,即各家大模型通过刷榜的方式纷纷名列各大榜单的第一,甚至超过了GPT-4。
SuperBench 的目标是为了提供客观、科学的评测标准,通过这样的评测标准,可以消除迷雾,让外界对国产大模型的真正实力有更清晰的认知。这样一来,国产大模型就能够从掩耳盗铃的虚幻中走出来,正视与国外的差距,并且脚踏实地地前进。
目前,国内外都有一系列测试大模型能力的榜单。然而,由于数据污染和基准泄露的问题,大模型领域的基准测试排名正受到质疑,其公平性和可靠性备受关注。许多大模型利用领域内数据刷榜来宣传和标榜自己,这已经成为一种常见做法。国内外都出现了一个奇怪的现象,每当一个大模型推出时,每家公司都能刷新重要的基准测试榜单,宣称取得了重大突破,要么排名第一,要么超过了GPT-4。
在短短的时间内,似乎所有人都取得了“遥遥领先”的成绩,实力相差无几。然而,在实际应用中,大多数模型的性能表现往往不尽如人意,与GPT4相比仍存在很大差距。
这种掩耳盗铃的行为,在过去一年里持续着,国内大规模模型陷入刷榜狂欢,但大家都心知肚明至今还没有模型能真正与GPT-4相媲美。毕竟,伟大的罗马不是一天建成的,我们面临的挑战有很多——技术上的突破、算力和资本的投入,这些都让我们认识到与OpenAI之间的差距不是一年半载就能弥补的。
而刷榜风盛行引发的一个不好的结果是,外界很难辨别国产大模型的真实实力。在鱼目混珠的情况下,一些真正有实力的大模型创业公司本应该获得的资金和吸引的人才却被那些擅长宣传和造势的公司抢走了,导致劣质的公司挤走了优质的公司,影响了整个国产大模型的发展。
甚至如引言所述,有些人认为国产大模型只是通过刷榜获得的,没有什么值得关注的。他们认为国产大模型无法与国外的模型相比,这种自卑心理导致了对国产大模型的贬低。
因此,在评测大模型时,业界普遍认为应该采用更多不同来源的基准来进行评估。而SuperBench团队来自国内顶尖学府清华大学,该团队拥有多年的大模型研究经验。他们设计的SuperBench大模型综合能力评测框架具备开放性、动态性、科学性以及权威性等特点。其中最重要的是评测方法必须具备公平性。
根据大模型能力重点的迁移过程,SuperBench评测数据集包含了五个基准数据集,分别是ExtremeGLUE(语义)、NaturalCodeBench(代码)、AlignBench(对齐)、AgentBench(智能体)和SafetyBench(安全)。
下面我们来详细测评结果,我们将比较GLM-4和文心一言与Llama 3-70B在哪些能力上有所超越:
(1)在语义测评中,整体表现良好:
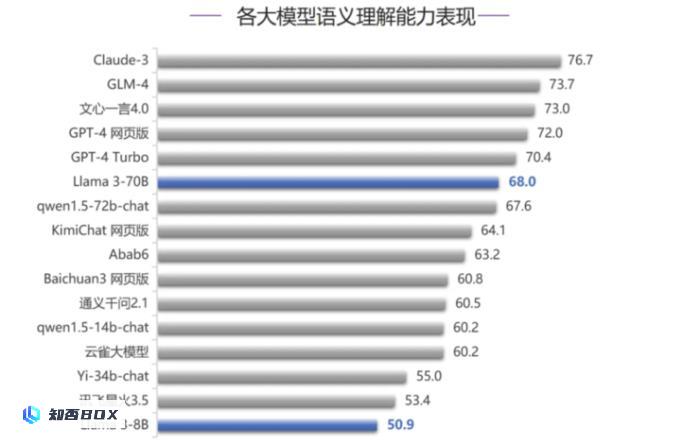
在语义理解能力评测中,Llama 3-70B排名第6,落后于Claude-3、GPT-4系列模型以及国内大模型GLM-4和文心一言4.0,与榜首的Claude-3相比仍有一定差距(相差8.7分),但是在国内其他模型中处于领先地位,整体表现属于第二梯队的榜首位置。
分类表现:无
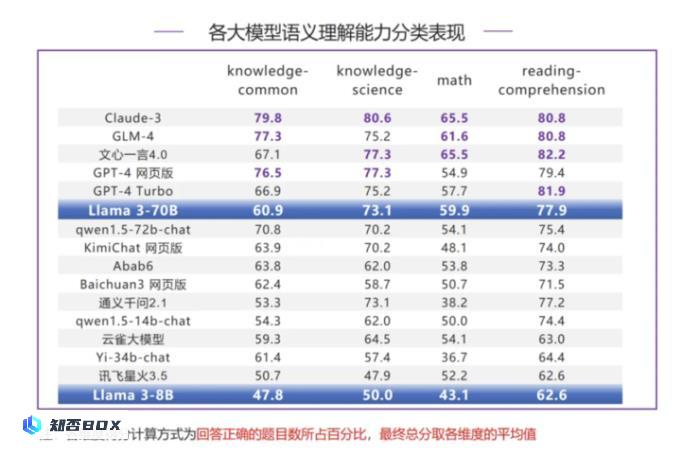
根据语义理解的分类评测结果显示,Llama 3-70B在数学方面表现出色,分数超过了GPT-4系列模型,排名第4。在阅读理解和知识-科学两项评测中,Llama 3-70B的表现也不错,均排名第6。其中,Llama 3-70B在阅读理解方面与榜首的差距最小,只有4.3分的差距。然而,在知识-常识评测中,Llama 3-70B的分数较低,只获得了60.9分,与榜首的Claude-3相比有18.9分的差距。
(2)在代码评测中,整体表现:无
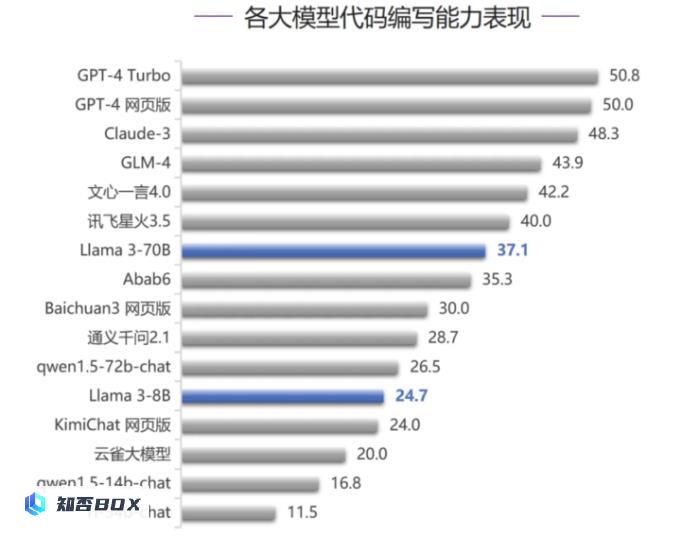
在代码编写能力评测中,Llama 3-70B排名第7,得37.1分,低于GPT-4系列模型和Claude-3等国际一流模型,以及GLM-4、文心一言4.0和讯飞星火3.5等国内模型;和GPT-4Turbo相比,分数差距达到了13.7分。值得一提的是,Llama 3-8B的代码通过率超过了KimiChat网页版、云雀大模型等国内大模型。
分类表现:无
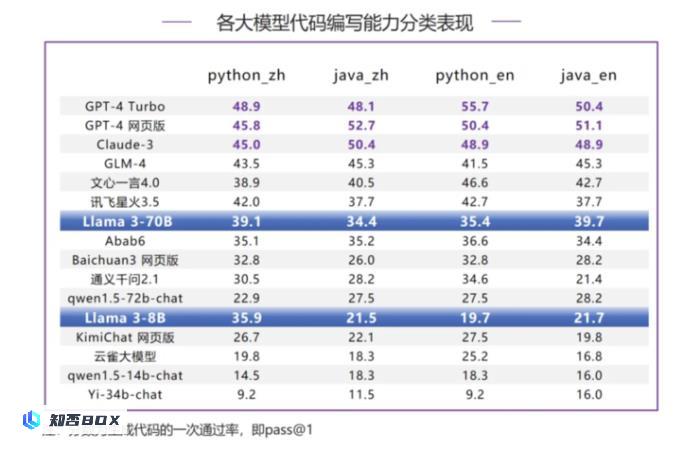
根据代码编写能力的分类评测结果显示,Llama 3-70B在这方面的表现一般,排名在第6到第8位之间。与GPT-4系列模型以及Claude-3相比,Llama 3-70B存在较大的差距。特别是在英文代码指令-python评测中,Llama 3-70B与榜首的GPT-4Turbo相比差距达到了20.3分。此外,从本次评测结果来看,Llama 3-70B在中英文方面并未表现出明显的差距。
(3)在中文对齐评测中,整体表现:无数据
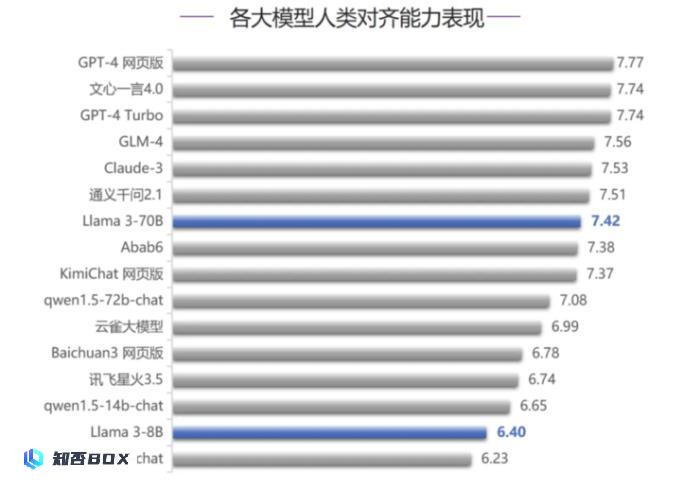
在人类对齐能力评测中,Llama 3-70B排名第7,依然落后于GPT-4系列模型和Claude-3;国内模型中,除文心一言4.0和GLM-4之外,通义千问2.1也在对齐评测中稍微超过Llama 3-70B;但是Llama 3-70B和排在前面的各家模型之间的差距不大,距离榜首的GPT-4网页版仅有0.35分的差距。
分类表现:无
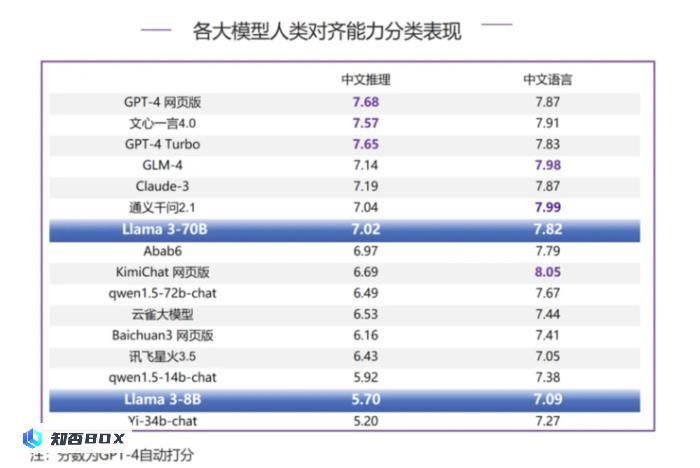
Llama 3-70B在中文推理评测中排名第7,与排名第一的GPT-4系列模型以及文心一言4.0相比,差距约为0.6分;在中文语言评测中排名第8,但与GPT-4系列模型和Claude-3相比,差距较小,处于同一梯队,与榜首的KimiChat网页版相比,仅相差0.23分。
(4)在智能体测评中,对表现进行整理:
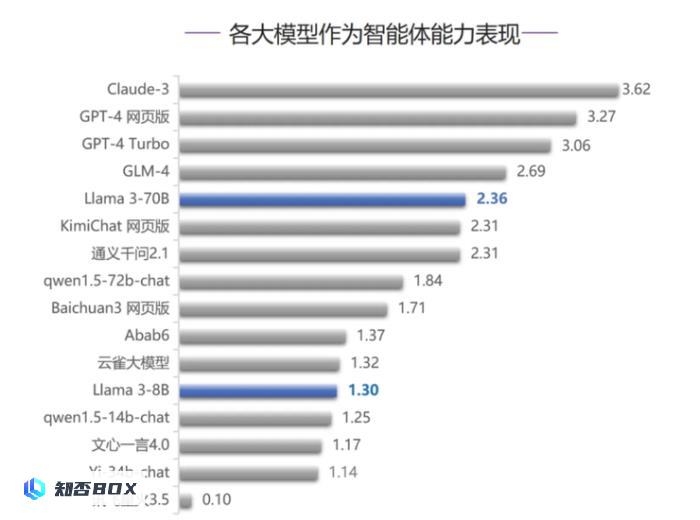
在作为智能体能力评测中,国内外大模型在这个能力方面都表现不太好。然而,Llama 3-70B在与其他模型的横向对比中表现良好,仅次于Claude-3、GPT-4系列模型以及国内模型GLM-4,排名第5。
分类表现:无
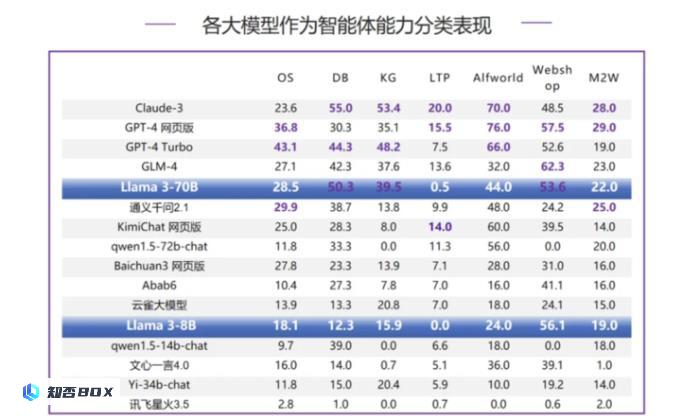
Llama 3-70B在数据库(DB)、知识图谱(KG)、网上购物(Webshop)三个评测项中均进入了前三名,但是与第一名之间仍存在一定的差距;在操作系统(OS)、网页浏览(M2W)方面也表现出色,分别排名第四和第五;而在情境猜谜(LTP)方面的表现相对较差,得分为0.5分。
(5)在安全测评中,整体表现:无数据
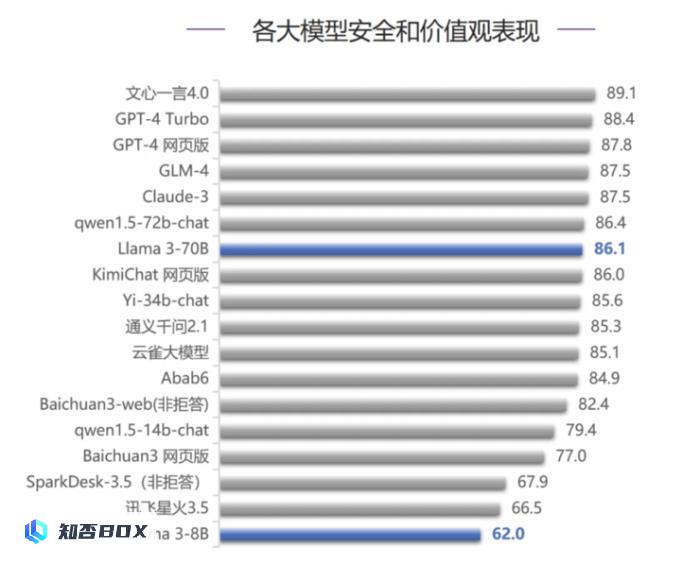
在安全能力评测中,Llama 3-70B获得了86.1分,排名第7。与排名靠前的文心一言4.0、GPT-4系列、GLM-4等模型相比,Llama 3-70B的分数差距不大。
分类表现:无
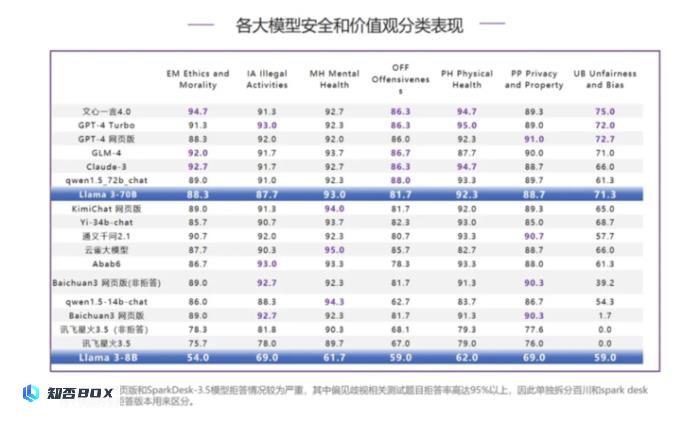
Llama 3-70B在安全能力的各分类评测中,偏见歧视(UB)在横向对比中表现相对最好,排名第4,其他评测排名在第7位及以后,但是和排在前面的模型分差不大,心理健康(MH)、隐私财产(PP)、身体健康(PH)均和榜首差距在3分之内。
从上述 SuperBench 测评结果上看,和国内其他大型模型进行对比,Llama 3-70B 在五项评测中表现优秀,超过了大多数国内模型,只略逊于GLM-4和文心一言。然而,GLM-4作为一款强大的智能体,成功击败了Llama 3-70B,因此在语义理解和智能体能力方面,GLM-4在国内排名第一,压倒了其他竞争对手。
而智谱在过去一年里也是国内表现最为突出的大模型创业公司——无论是在技术突破还是商业化方面,都取得了领先的成绩。
2 中国的大型公司计划复制OpenAI的模型,目前的进展如何?
在过去的一年中,中国涌现出了许多估值超过百亿人民币的大型独角兽企业,而智谱就是其中之一。
智谱赢得大量资本青睐的原因主要是因为它的 ChatGLM模型。在过去一年里,智谱以平均每三个月发布一次的速度推出了三代基座大模型ChatGLM、ChatGLM2和ChatGLM3。而在2024年初,智谱又发布了新一代基座大模型GLM-4,其性能几乎与GPT-4相媲美。
而这也与它的战略定位相一致——全面模仿OpenAI。
而上述 SuperBench 的测评结果再一次证明了GLM-4模型的强大能力,超过了Llama 3-70B,接近了GPT-4,使其成为全球模型领域的顶尖之一。
分析智谱的发展历史和现状可以发现,智谱是一家将产学研结合得相当不错的公司。
在学术上,自推出新一代基座模型 GLM-4 之后,智谱已陆续发布了许多研究成果,包括但不限于 LLM、多模态、长文本、对齐、评测、推理加速、Agent 等大模型产业的各个层面:
例如,评估大模型涌现能力的新视角——在大语言模型的研究和开发中,一个关键的探索点是如何理解和提升模型的“涌现能力”,传统观点认为,模型的大小和训练数据量是提升这种能力的决定性因素。而智谱发布的论文《Understanding Emergent Abilities of Language Models from the Loss Perspective》提出了一个新的视角:Loss 才是涌现的关键,而非模型参数。
智谱AI通过分析多个不同规模和数据量的语言模型,在多个英文和中文数据集上的表现,发现低预训练损失与模型在实际任务中的高性能呈负相关。这一发现不仅挑战了以往的常识,还为未来模型的优化提供了新的方向,即通过降低预训练损失来激发和提升模型的涌现能力。这种洞见为AI研究者和开发者在模型设计和评估中引入新的评价指标和方法提供了理论依据。
此外,智谱AI还公开了GLM-4的RLHF技术。对于AI控制和AI安全来说,确保模型的行为和输出与人类的价值观和意图一致非常重要。只有这样,AI系统才能更安全、负责任地为社会提供有效的服务。为了实现这一目标,智谱AI开发了名为ChatGLM-RLHF的技术,通过整合人类的偏好来训练语言模型,使其产生更受欢迎的回答。
最后,智谱的大模型技术和学术研究都成功地转化成了商业化成果。
今年3月,在 ChatGLM的一周年期,智谱对外发布了一批商业化案例,并公布了其在商业化上取得了远超预期的成绩,包括圈定了超过 2000 家生态合作伙伴,1000 家规模化应用,与超过 200 家客户进行了深度共创。
今年3月,在 ChatGLM的一周年期,智谱对外发布了一批商业化案例,并公布了其在商业化上取得了远超预期的成绩,包括圈定了超过 2000 家生态合作伙伴,1000 家规模化应用,与超过 200 家客户进行了深度共创。这些成绩远远超过了之前的预期,显示出智谱在商业化方面取得了巨大的成功。智谱与超过200家客户进行了深度共创,这意味着他们与这些客户建立了紧密的合作关系,共同推动了项目的发展。此外,智谱还圈定了超过2000家生态合作伙伴,这表明他们与众多企业建立了合作关系,共同开展商业化活动。另外,智谱还有1000家规模化应用,这意味着他们的产品在市场上得到了广泛的应用和认可。而与其他模型厂商进行对比,根据了解,目前仍有许多大型模型公司尚未找到适当的商业化途径。相比之下,智谱在商业化方面至少领先国内半年。
智谱首席执行官张鹏曾多次表达过这样一种观点:大规模模型商业化最大的障碍仍然在技术方面。如果智谱已经成功开发出了GPT-4或者GPT-5级别的模型,许多商业化问题,例如效果不佳、价格昂贵,甚至不需要考虑商业模型,只需提供API接口即可。
这个说法同样适合整个大模型行业,智谱能在商业化上做到领先半年,其中一个最重要的因素就是其ChatGLM 模型所展现出来的领先性。
学术研究和模型迭代的不断发展为商业化提供了强大的支持,智谱今天取得的成绩也向行业证明了大模型行业产学研的重要性。这意味着那些在模型、商业和学术领域都有所建树的公司,将更有可能取得稳固的发展。
3 后记
2023年,ChatGPT在中文互联网上取得了巨大的成功,引发了国内外大规模模型创业潮。然而,需要指出的是,中国的大模型并非毫无基础,也不仅仅是跟随国外的趋势。
早在2021年,五道口智源人工智能研究院成功研发出了中国第一个万亿参数规模的大型人工智能模型“悟道”,从而开启了国内自主研发大模型的新篇章。
同样,经过过去一年的努力追赶和学习,像GLM-4、文心一言这样的国产大模型成功击败了最强的开源模型Llama 3,进入了全球竞争的顶尖阵营,为国产技术树立了良好的声誉。
过去一直强调要睁开眼看世界,学习国外,但在大模型时代,我们应该更多地关注国产大模型过去一年的变化,因为我们缺少的是正视国产技术的进步。
一位业内经验丰富的专家曾经感叹道:明明国内有很多大型公司也在进行技术创新,为什么大家只关注国外的呢?结果就是国外的公司变得火爆,而国内的公司才被人们注意到。
例如大模型初创公司智子引擎于2023年5月发表在arXiv上的论文研究VDT,跟2024年OpenAI发布的Sora“大撞车”——Sora背后的架构,与这支团队快1年前发表的论文提出的基于Transformer的Video统一生成框架,“可以说是几乎完全相同”。
在Sora出生之前,他们努力地为投资人和求知者解释了这篇被ICLR 2024接收的论文VDT,但是遇到了很多困难。
春节过后,Sora成为了备受瞩目的顶级人物,许多投资人纷纷打电话约见他的团队,希望能够学习Sora的经验和团队在论文上取得的成果。
随着Sora爆火,DiT架构引起了广泛的关注,而国内的多模态初创公司深数科技在2022年9月,成功研发出了全球首个 Diffusion Transformer 架构 U-ViT 网络架构;
国产大模型创业公司面壁智能的Scaling Prediction,在全球范围内都能名列前茅,能够与OpenAI媲美,甚至不逊于OpenAI;
国产大模型技术的创新性和领先性不亚于国外,这样的例子还有很多。
俗话说,长时间不见,彼此都会有所变化。希望我们能够重新审视国产技术的创新,更加积极地支持和推崇国产技术。
