大模型推理速度提升 50% 以上,还能保证少样本学习性能!
小米大模型团队提出 SUBLLM(Subsampling-Upsampling-Bypass Large Language Model),国际 AI 语音大牛、开源语音识别工具 Kaldi 之父 Daniel Povey 也参与指导。
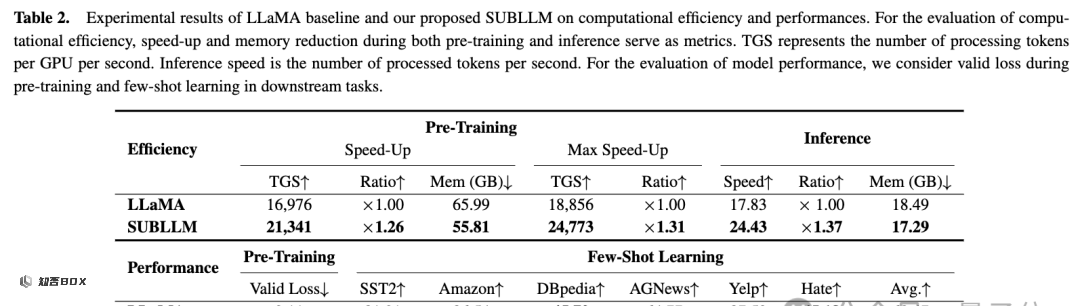
与 Llama 等模型相比,SUBLLM 在训练和推理速度以及降低内存方面都有了显著提升。
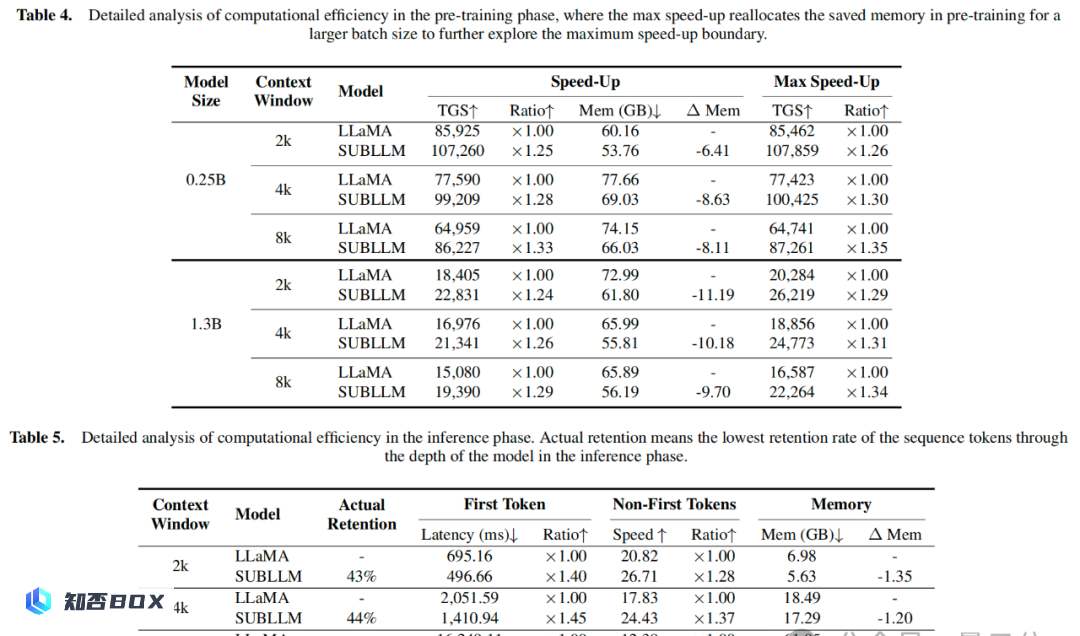
在大模型训练中,SUBLLM 的速度提高了 26%,每个 GPU 的内存减少了 10GB。在推理中,它的速度提高了 37%,每个 GPU 的内存减少了 1GB。训练和推理速度分别最高可以提高至 34% 和 52%。
SUBLLM 通过智能地选择和处理数据,使得模型在训练和推理时更加高效:子采样模块剔除不必要的信息,上采样模块恢复数据的完整性,而绕过模块则加快了学习过程。

在一万字中挑选最关键的五百字
目前,云端的大模型处理超长文本任务,通常需要动用多达 8 个 GPU,这个过程不仅耗时,而且成本昂贵。如果将大模型类比于人脑,那么当前大模型的运行功率相比于人脑运行功率的 100 倍以上。
在语音识别领域,Daniel Povey 提出了 Zipformer,它可以通过最低压缩 16 倍的帧率,实现与更大模型一致甚至更高的语音识别率,从而在语音识别领域起到了“四两拨千斤”的作用。
小米集团大模型团队试图将这一思路扩展到大型语言模型中,在不影响性能的情况下,实现了更高效率的大模型运算。
总的来说,SUBLLM 的工作原理通过引入子采样、上采样和旁路模块等方式,对计算资源动态分配,从而减少了冗余的 token 计算负担,加速了模型的训练和推理过程。
能做到就像在一万字中挑选最关键的五百字一样,保留文本中必需的部分,删减其中的冗余,从而让大模型所需处理的文本更短。

就实现路径而言,会将子采样模块根据 token 的重要性分数对其进行筛选,保留重要的 token 并丢弃不重要的部分。
同时,旁路模块通过结合子采样前后的序列,进一步提高了模型的收敛速度。这种设计不仅显著减少了计算成本,还保持了输入序列的语义完整性。
随后,就像我们能通过只言片语补充完整故事的来龙去脉,SUBLLM 也能将精简后的信息恢复到原有的完整度,确保整个文本在表达时的连贯与完整。在处理信息时,SUBLLM 还能更加迅速地找到最佳的表达方式。
接下来详细观察SUBLLM的模型结构。
SUBLLM 具体长啥样?
前不久,谷歌 Deepmind 提出了 mixture of depths(MoD)模型结构,MoD 使用静态计算预算,使用每个块的路由器选择 token 进行计算,并通过对自注意力和 MLP 块或残差连接的选择来优化 FLOP 使用。
更早以前,经典论文 CoLT5 使用条件路由来决定给定 token 是通过轻量分支还是重量分支在前馈和注意力层中传递,以便将更多资源分配给重要 token。
与这些模型结构相似,SUBLLM 采用的原理类似于人类大脑对信息的处理方式。
人脑有两种思维模式,一种低功耗的快速模式,一种高功耗的慢速模式,分工明确,且两种模式恰恰使用的是同一个脑部区域。
因此,SUBLLM 作者也从这一信息处理模式的角度思考了如何将大模型的算力进行合理地分配:重要的 token 用全部算力,相对不重要的 token 使用更少算力。
具体来说,SUBLLM 的模型结构是基于 decoder-only 的大语言模型架构,在不改变原有模型结构的基础上,在一些特殊的层上进行了结构升级。
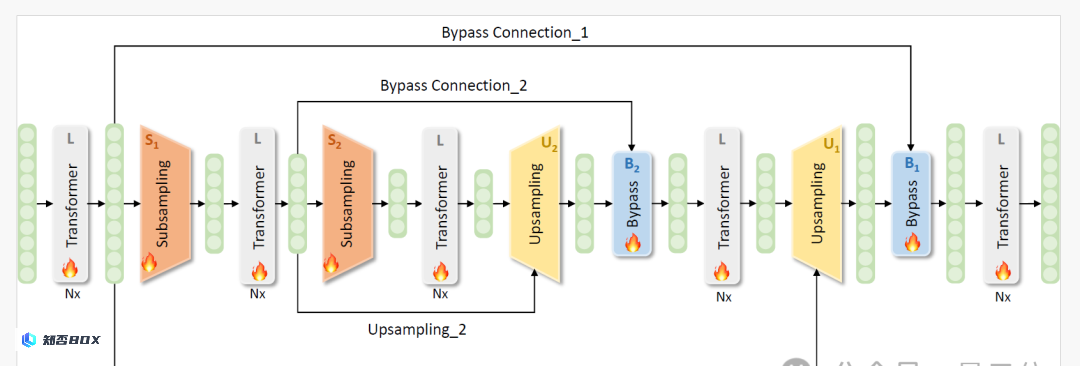
为了有效地管理需要处理的令牌数量,子采样和上采样模块已经被整合到Transformer块之间。
首先,模型使用几个Transformer块处理完整序列,捕获全面的token序列表示。引入子采样模块后,这些模块暂时去除不关键的token,从而减少处理所需的序列长度。
然后对减少后的序列进行更多次的子采样过程,也就是序列的减少是嵌套的。序列压缩的最高级别发生在网络的最中间的 Transformer 块中。
随后,使用上采样模块逐步增加序列长度。这些模块将较短的处理序列与子采样前的原始序列合并,将它们恢复到完整长度。
这种机制允许仅解码器模型作为语言模型操作,按顺序生成 token,保证输入和输出序列长度相同。
此外,经过上采样过程后,系统集成了绕过连接模块,以利用每个子采样前的嵌入,有助于改进从子采样到上采样的学习过程。
随后的实验证实,这种方法显著提高了收敛效率。
与 LLaMA模型相比,SUBLLM 在训练和推理方面分别实现了 26% 和 37% 的速度提升,同时显著降低了内存成本,同时保持了性能。
预训练阶段、推理阶段计算效率的详细分析: