扎克伯格提到,Meta的人工智能投资规模巨大,Llama 3模型目前在训练计算能力方面已经消耗了“数亿美元”,预计未来成本将进一步增加。他指出,“未来的投入将达到数十亿美元”,但Meta仍然愿意在人工智能的“军备竞赛”中投入资金。
“我认为现在很多公司都存在过度建设的情况,当你回头看时,你会想,‘哦,我们可能都花了比实际多几十亿美元的钱,’”扎克伯格说,但“另一方面,实际上,我认为所有投资的公司都在做出理性的决定。因为你一旦落后,就无法在未来10到15年内掌握最重要的技术。”
据马克·扎克伯格所述,一旦完成所有投资,Meta将会免费向公众开放Llama背后的技术,只要使用者遵守“可接受使用政策”。他希望通过开源策略,将Meta打造成其他成功创业公司和产品的基石,以在行业发展中发挥更大影响力。然而,Meta仍将保留用于训练Llama 3.1数据集的保密性。
彭博社报道称,有些批评者担心,Meta的人工智能开源模型可能会被滥用,同时还担心来自中国等美国“地缘政治对手”的科技公司会利用这一技术来追赶美国同行的步伐。
不过,扎克伯格更为担忧的是,如果将美国的人工智能技术与其他世界地区隔绝开来,最终可能会适得其反。
“有一种想法是,‘好吧,我们需要把一切都锁起来,’”扎克伯格表示,“我认为这是错误的,因为美国是在开放和分散的创新中蓬勃发展起来的……所以我认为,把所有事情都封锁起来,反而会阻碍我们继续进步,最终让我们更有可能失去领导者地位。”
他进一步表示,认为美国在人工智能领域将领先中国数年的观点,“也是不切实际的”,美国将通过略微领先的“累积”获得明显的技术优势。

自ChatGPT爆火以来,将其开源的呼声未曾断绝。可就在ChatGPT2发布之后,OpenAI选择了闭源发展。阿里云、智谱和清华EKG、百川智能等,选择了开源,华为则出于数据隐私和商业收益考虑,盘古大模型就选择了闭源,在这场全球大模型军备赛中,有关开源发展和闭源深耕的争论不止不休。
在同一天(23日)发布的公开信中,扎克伯格表达了相同的看法。
扎克伯格指出,开源将确保全世界更多的人能够享受人工智能带来的好处和机会,权力不会集中在少数公司手中,并且该技术可以更均匀、更安全地应用于整个社会。他认为,最好的策略是建立一个强大的开放生态系统,使得行业领头公司与政府和盟友密切合作,以确保在长期内实现可持续的先发优势。
关于中国,他在公开信中提到,“有些人认为,美国必须采用闭源,以防止中国获得这些模型”,但“这是行不通的,只会让美国及其盟友处于不利地位”。
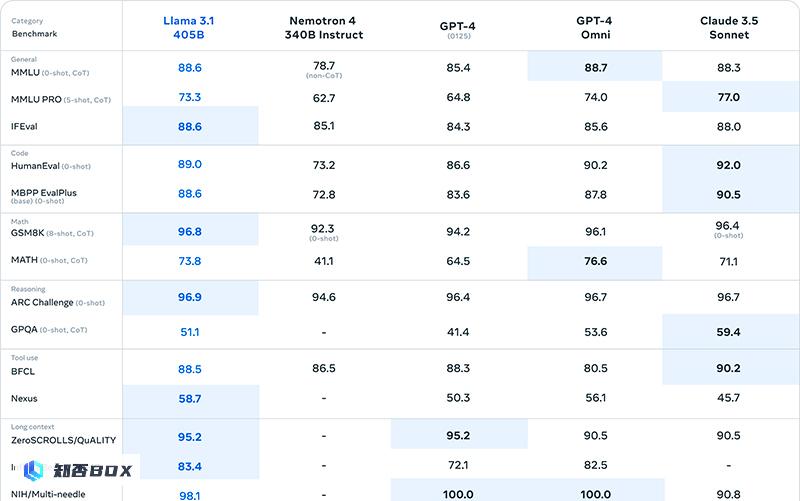
Llama 3.1 405B与其它模型在多个基准上的评估进行对比,详细内容可查看Meta官网。
近年来,中国高等院校和企业在人工智能领域取得了快速发展。今年5月初,美国乔治敦大学安全与新兴技术中心(CSET)发布的研究结果显示,在当前世界超过一半的人工智能研究领域中,“中国的研究领先美国”。数据表明,无论是人工智能研究论文的总数量,还是高引用率的论文数量,中国的机构都名列前茅。
“中国在人工智能研究领域绝对处于世界领先地位,且在很多领域都可能是世界领先者,”CSET团队分析主管扎卡里·阿诺德补充说,现在,中国在一系列AI研究领域都很活跃,包括越来越多的基础研究。
7月3日,联合国世界知识产权组织(WIPO)称,中国在聊天机器人等生成式人工智能(AI)发明方面远远领先于全球其他国家,过去十年间申请的生成式人工智能(AI)专利数量超过3.8万份,是美国(6276份)的六倍。
世界知识产权组织专利分析经理克里斯托弗·哈里森表示:“这(生成式AI)是一个蓬勃发展的领域,也是一个增长速度越来越快的领域……数据表明,该领域将对未来许多不同的工业部门产生深远影响。”他指出,中国专利申请范围非常广泛,涵盖了从自动驾驶、出版,再到文件管理。
