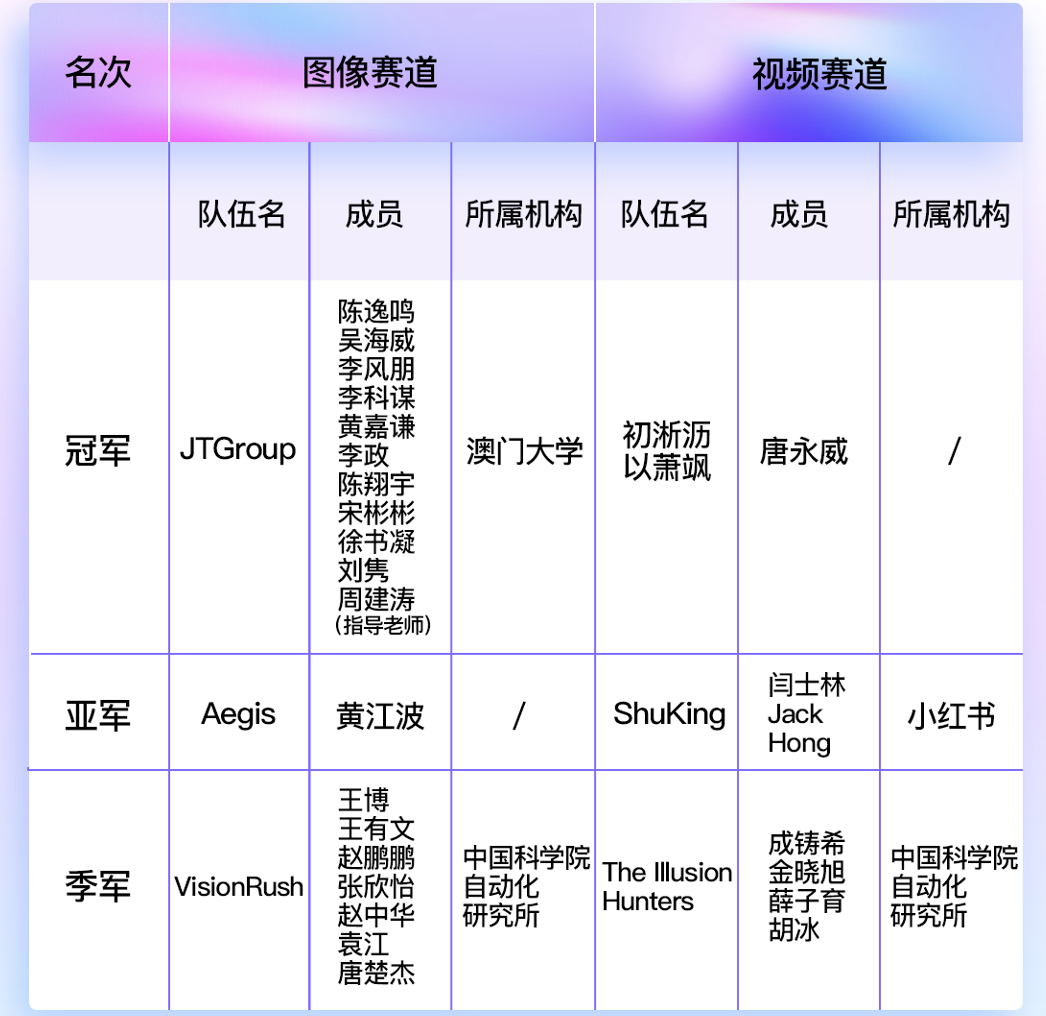
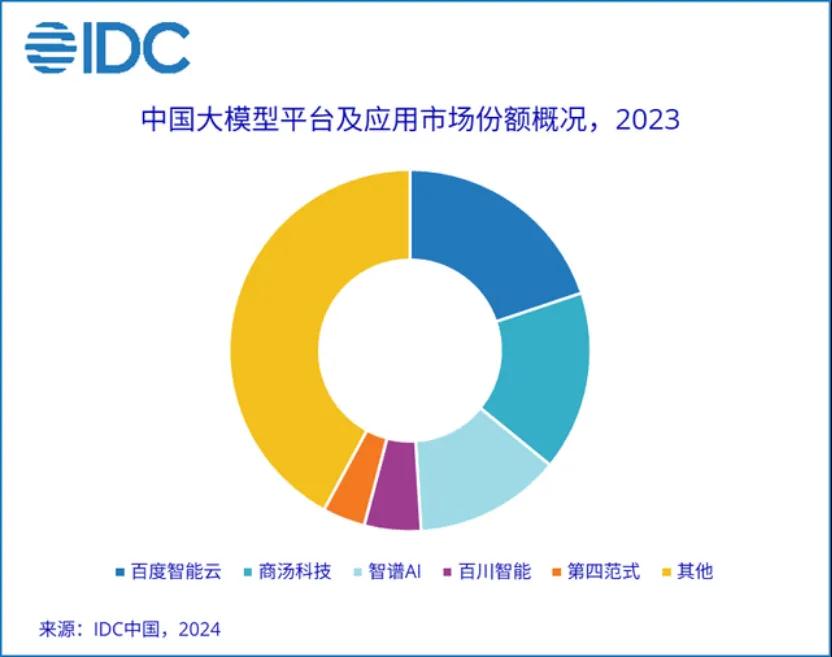
评估大型模型的可用性是一个复杂的过程,涉及到多个方面的考量,包括准确性、效率、稳健性、可解释性和伦理等。虽然目前没有一个统一的自动化方案能够全面评估所有方面,但是有一些工具和方法可以用于自动化评估模型的某些特性。以下是一些常用的自动化方案和工具:
单元测试和集成测试:对于模型的不同组件,可以使用单元测试来验证其是否按预期工作。集成测试则可以确保不同组件在一起时也能正常工作。 基准测试和数据集:使用标准的数据集和基准测试来评估模型的性能。例如,对于自然语言处理模型,可以使用GLUE、SuperGLUE或SQuAD等数据集。模型卡片(Model Cards):模型卡片是一种文档,用于记录模型的性能、训练数据和预期的使用场景。这可以帮助用户了解模型的适用性和限制。连续集成/连续部署(CI/CD):使用CI/CD工具来自动化模型的测试和部署过程。例如,使用Jenkins、GitHub Actions或GitLab CI/CD来自动化测试和部署流程。自动化性能监控:使用工具如Prometheus和Grafana来监控模型的性能指标,如延迟、吞吐量和准确性。 自动化回归测试:使用工具来定期运行回归测试,以确保模型的更新不会引入新的错误。可解释性和可视化工具:使用工具如LIME、SHAP或Captum来解释模型的决策,并使用TensorBoard等工具来可视化模型的训练过程。 伦理和偏见检测:使用工具来检测模型输出中的偏见和伦理问题。例如,可以使用IBM的AI Fairness 360工具来检测和减轻机器学习模型中的偏见。模拟和沙盒环境:在模拟环境中测试模型的性能,以避免在实际部署中出现问题。 云服务和平台:使用云服务提供商(如AWS、Google Cloud Platform、Azure)提供的自动化工具来部署和管理模型。虽然这些工具和方法可以自动化评估模型的某些方面,但通常还需要人工参与来综合评估模型的可用性,特别是在涉及模型的可解释性和伦理问题时。因此,自动化方案应该与人工审核相结合,以确保模型的全面评估。