AIGC动态欢迎阅读
原标题:Mamba一作再祭神作,H100利用率飙至75%!FlashAttention三代性能翻倍,比标准注意力
快16倍
关键字:矩阵,注意力,乘法,速度,性能
文章来源:新智元
内容字数:0字内容摘要:
新智元报道编辑:编辑部
【新智元导读】时隔一年,FlashAttention又推出了第三代更新,专门针对H100 GPU的新特性进行优化,在之前的基础上又实现了1.5~2倍的速度提升。FlashAttention又有后续了!
去年7月,FlashAttention-2发布,相比第一代实现了2倍的速度提升,比PyTorch上的标准注意力操作快5~9倍,达到A100上理论最大FLOPS的50~73%,实际训练速度可达225 TFLOPS(模型FLOPs利用率为72%)。
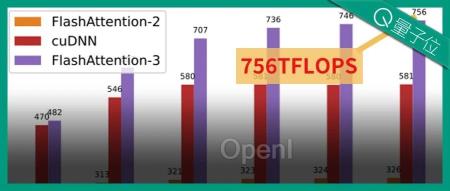
然而,去年发布FlashAttenion-2尚未运用到硬件中的最新功能,在H100上仅实现了理论最大FLOPS 35%的利用率。
时隔一年,FlashAttention-3归来,将H100的FLOP利用率再次拉到75%,相比第二代又实现了1.5~2倍的速度提升,在H100上的速度达到740 TFLOPS。
论文地址:https://tridao.me/publications/flash3/flash3.pdf
值得一提的是,FlashAttention v1和v2的第一作者也是Mamba的共同一作,普林斯顿大学助理教授原文链接:Mamba一作再祭神作,H100利用率飙至75%!FlashAttention三代性能翻倍,比标准注意力快16倍
联系作者
文章来源:新智元
作者微信:AI_era
作者简介:智能+中国主平台,致力于推动中国从互联网+迈向智能+新纪元。重点关注人工智能、机器人等前沿领域发展,关注人机融合、人工智能和机器人革命对人类社会与文明进化的影响,领航中国新智能时代。