AIGC动态欢迎阅读
原标题:国产多模态大模型狂飙!颜水成挂帅开源Vitron,破解图像
/视频模型割裂问题
关键字:视觉,模块,任务,模型,图像
文章来源:智东西
内容字数:7520字内容摘要:
未来可探索三大方向:系统架构、用户交互性、模态能力。
编辑|ZeR0
奔向通用人工智能,大模型又迈出一大步。
智东西4月25日报道,近日,由颜水成教授带队,昆仑万维2050全球研究院、新加坡国立大学、新加坡南洋理工大学团队联合发布并开源了Vitron通用像素级视觉多模态大语言模型。
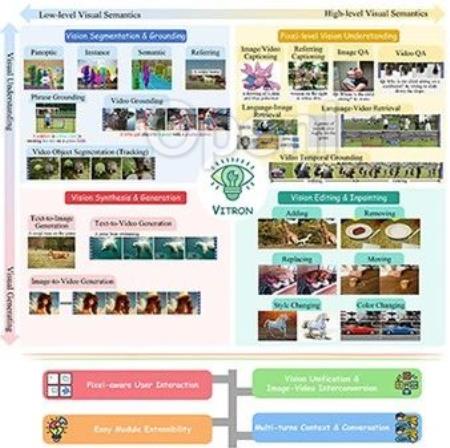
Vitron解决了困扰大语言模型产业已久的图像/视频模型割裂问题,支持从视觉理解到视觉生成、从低层次到高层次的一系列视觉任务,包括静态图像和动态视频内容进行全面的理解、生成、分割和编辑等任务,能处理复杂的视觉任务,擅长视觉理解和任务执行,同时支持与用户的连续操作,实现了灵活的人机互动。论文链接:https://is.gd/aGu0VV
开源代码:https://github.com/SkyworkAI/Vitron
该模型在四大视觉相关任务的功能支持及其关键优势如下:
这展示了通向更统一的视觉多模态通用模型的巨大潜力,为下一代通用视觉大模型的终极形态奠定了基础。
01.
应对视觉任务关键挑战,
提出大一统的多模态大语言模型
构建更通用、更强大的多模态大语言模型(MLLM)被视作通向通用人工智能(AGI)的必原文链接:国产多模态大模型狂飙!颜水成挂帅开源Vitron,破解图像/视频模型割裂问题
联系作者
文章来源:智东西
作者微信:zhidxcom
作者简介:智能产业新媒体!智东西专注报道人工智能主导的前沿技术发展,和技术应用带来的千行百业产业升级。聚焦智能变革,服务产业升级。