热爱科技的朋友们,欢迎点击关注
论文:Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation
会议:CVPR2018
问题①:这篇文章做什么的?
自答:这篇文章是CVPR2018上一篇关于弱监督语义分割的文章,也就是,数据集告诉你一堆图片以及这些图片里面有什么,你使用深度学习的方法将图片中每一个物体的区域分割出来。
问题②:这篇文章主要思路是什么?
自答:这篇文章首先通过一般的CAM方法生成分割seed cues(前面文章有介绍),然后利用这些seed cues中已经标记标签的pixel计算相似度标签,利用卷积神经网络提取图片每个像素的特征,计算这些特征之间的相似度,使用标签计算得到的相似度作为监督信息,从而训练网络,最后得到比较好的特征提取网络,使得图片中属于相同类别的像素的特征之间相似度较高,而不同类的像素相似度较低。
问题③:这篇文章突出特点是什么?
自答:我觉得是1)通过CAM计算相似度标签的方式,2)使用像素间相似度进行分割的算法。
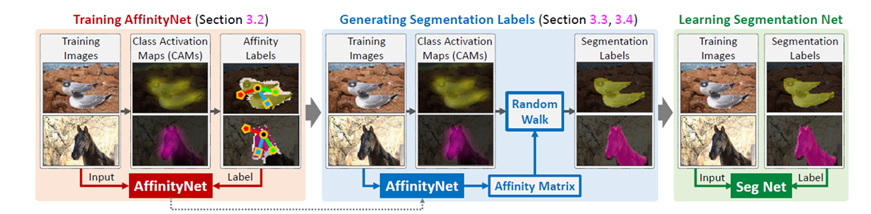
1、总体架构
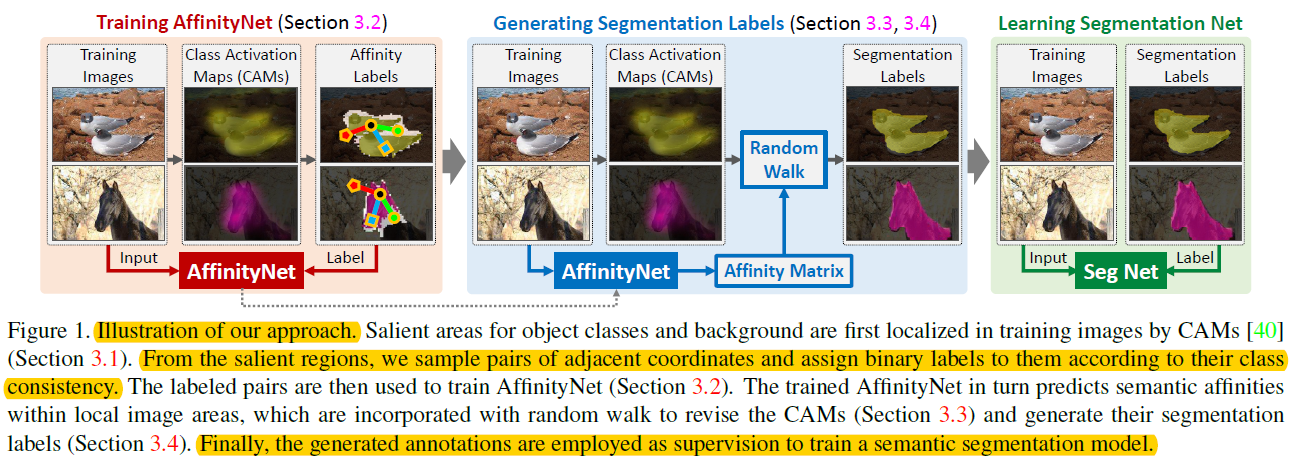
2、架构构成
第一步、计算CAM
目标类:
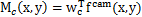
背景类:
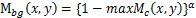
此中,α=16(4-24) à 根据Mc得到
也就是将feature maps 取最大值得到一个map,再归一化,1减去该feature map
如下图展示CAM方法的结果:

下图是生成的Seed cues(粉色和黑色区域是已确定标签区域):

第二步、生成语义相似度标签Semantic Affinity Labels
(1)设定半径为5,计算像素周围的一个圆内的像素与该像素之间(pixel pair)的相似度标签W。
计算方法图解:
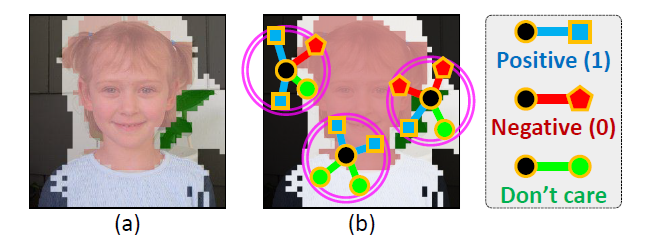
计算方法公式:

如图中所示,若pixel pair中有一个像素为未确定标签的像素,则忽略不考虑;若pixel pair中两个像素属于同一个类别则记为1,属于不同类别则记为0;如上图所示,存在于Foreground和Background的pixel,为红色和黑色的点,存在于Netural的点为绿色。
通过上面方法计算的Wij,作为相似度标签,Wij保存着位置相近的pixel pairs属于相同的class或者不同的class的信息。
第三步、AffinityNet Training
前提理论:位置相近的pixel更有可能属于同一个class;从确定的定位信息传播类别信息,处理物体区域假阳性和缺失块,生成训练标签。
(1)NetWork:
图片通过网络生成一堆features,faff 表示,这些feature maps中含有丰富的上下文信息,图片中每一个pixel对应着faff一个channel长的向量V,类别相同的pixel对应的V的内容更接近。
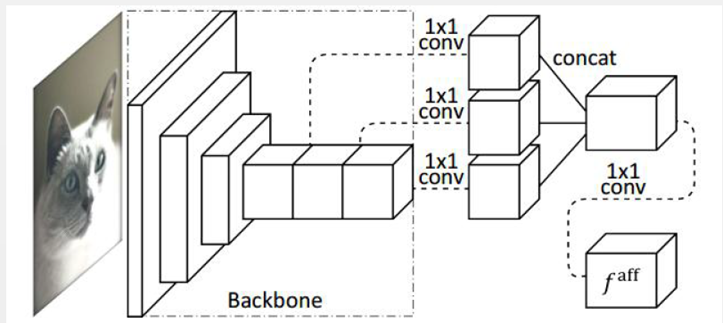
(2)如何训练?
1)首先,生成训练监督信息
2)需要什么?知道哪些pixel具有相同的或者不同的标签。
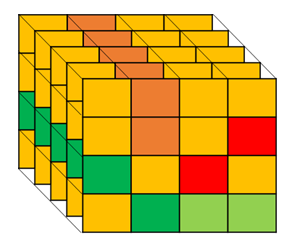
通过CAM计算得到相似度标签,可得到上图中的关系,相同标签为同颜色,不同标签为不同颜色,由相同label(同颜色pixel)和不同label(不同颜色pixel)的pixel pairs之间的相关性,通过训练指导不确定label(橙色pixel)与确定label 的pixel pairs之间的相关性。
这是一种通过周围有监督训练部分无监督的数据的一种方法。
(3)训练损失函数
(1)定义相关点集合P:d为欧式距离,γ为5
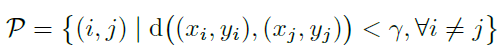
(2)将相关点集合P根据pixel pairs属于相同类还是不同类划分为P+和P-,其中集合P+划分为P+bg,和P+fg.
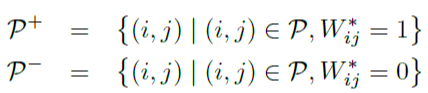
(3)损失函数
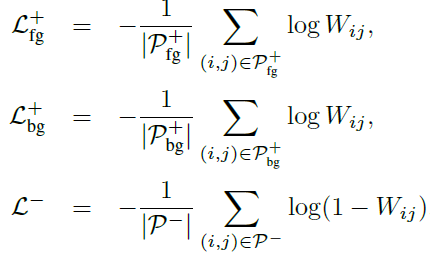
其中,
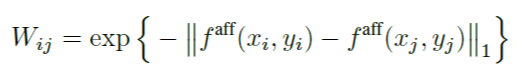
Pixel属于相同的class,则对应的提取的特征则越相似,属于不同class,则对应的提取的特征则越不同。
根据已确定的pixel pairs的相似关系,通过网络训练,得到不确定的pixels之间的关系。最终训练结束时,不确定标签的像素提取的特征也具有了一定的分布规律,与确定的某一类的标签pixel提取特征相似。
第四步、Revising CAMs Using AffinityNet
原理:计算不确定像素提取的特征与CAM确定类别的像素提取的特征之间像素度的均值,根据未知标签的像素与某一类的确定像素之间相似度值较大,则判定为某类。
即:(A1,A2,A3,…,An)为标签为A类的像素集;(B1,B2,B3,…,Bm)为标签为B的像素集,(P1,P2,P3,…,Pz)为未确定标签的像素集。计算P1与A类中所有像素的相似度的均值和P1与B类所有像素的相似度均值,比较两个值的大小,判定P1是属于A类还是B类。

第五步、训练分割网络
使用计算得到的相似度,得到分割标签,作为全监督训练的检索信息,选用分割网络进行全监督语义分割训练,得到最终的分割结果。
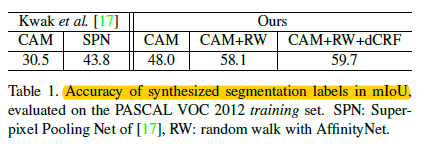
3、结果
(1)CAM和AffinityNet的分割结果
(2)最终分割结果

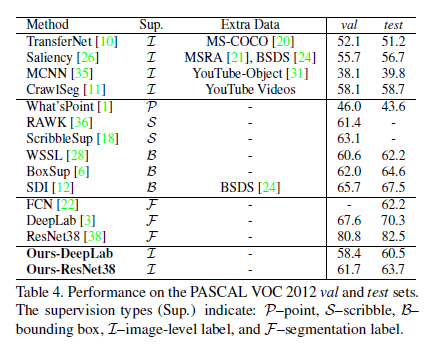
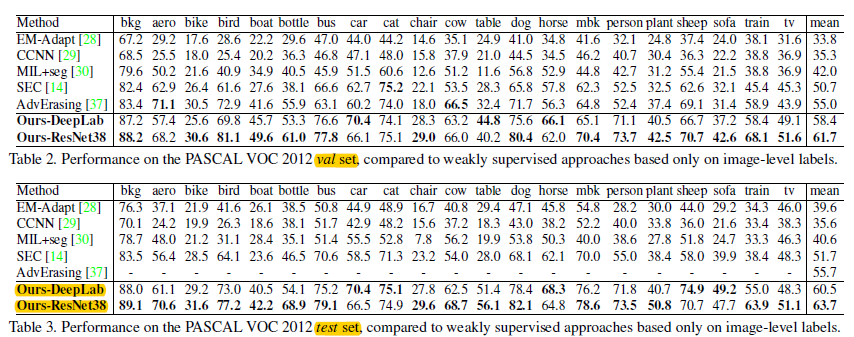
(3)在PASCAL VOC2012上的结果
更多详细信息请查看原文,论文地址:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Ahn_Learning_Pixel-Level_Semantic_CVPR_2018_paper.pdf
这篇文章便介绍到这里啦,为了更方便管理文章,同名微信公众号已经上线,喜欢使用微信的朋友们,欢迎大家关注!