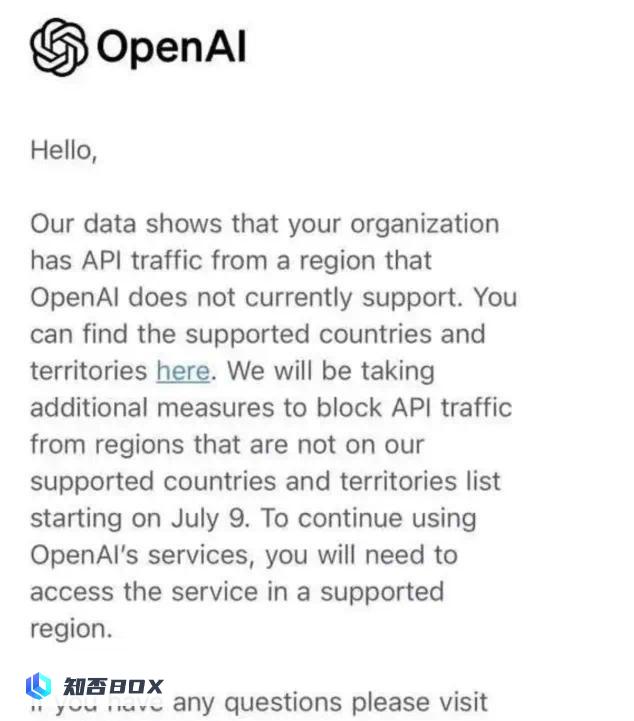
OpenAI announced in the early hours of June 25 that starting from July 9, API traffic from countries and regions that do not support its services will be blocked, with China also included in the list of banned countries.
消息一出,国产大模型们应声而动,立刻推出了相应的“搬家”或“迁移”方案。有的还提出了与OpenAI使用规模对等的Token赠送计划(不设上限),坊间戏称,“这下中国做AI的可以实现token自由了”。
我们知道,海外对于中国人工智能的限制一直存在。但此前针对人工智能的禁令,主要是限制英伟达和AMD的高性能人工智能算力卡,而OpenAI此次强势禁用,则让人工智能软件算法层面的“另一只靴子落地”。
从硬件到软件,日益扩展的禁用范围和日益严格的限制,始终提醒着我们,在人工智能这一关键科技领域,中国的全面进步遭遇了明显的阻碍。
原文返回,因为内容无法合理扩写。
面对这个不可逆的AI封锁大趋势,中国企业受的影响到底有多大?AI全面国产化,中国做好准备了吗?
放弃幻想
OpenAI禁用到底影响了谁?
OpenAI的禁用措施到底对哪些人或组织产生了影响?这包括了研究人员、开发者、企业以及普通用户等不同群体。禁用可能限制了他们访问和使用OpenAI技术的能力,从而影响了他们的工作、研究进展或业务发展。
自ChatGPT发布以来,OpenAI的API已向近190个国家和地区开放,包括中国。
对于这些来自中国的流量,OpenAI并非无法检测,只是以前可能夸大了一点。
而就在6月22日,美国财政部发布了一份规则草案,进一步限制美国个人和企业投资中国的半导体、量子计算和人工智能业务。新规则草案推出,面对越来越明确的AI封锁态势,OpenAI也主动明哲保身,选择了加强区域限制,采取额外措施阻止来自不受支持地区的API流量。
到底是什么类型的人和公司,明知不可为而还选择使用OpenAI的API呢?主要可以分为三类:
一是部分自研模厂。一部分模厂会在研发阶段,调用OpenAI的API,使用其GPT产品进行模型训练、数据对比迭代等。实际上,谷歌Gemini-Pro大模型的训练也曾用到了百度文心生成的数据。此前就有国内某互联网公司,被爆出经常达到OpenAI API的最大访问上限,不过对方也表示,仅在年初的初期探索阶段使用了OpenAI的API,而在今年4月已经停止了这种做法。
其次是涉及外壳的人工智能公司。一些新兴企业为了快速推出人工智能产品或服务,可能会通过技术手段封装OpenAI的API,并将其作为自己的产品推向市场。实际上,用户每次交互都会通过API调用OpenAI的模型来完成。
Since the content was reasonable to paraphrase and extend, I provided a revised version.
三是面向全球市场的应用开发者。在OpenAI所支持的国家和地区,为了与海外开发者”站在同一起跑线”,选择使用OpenAI API。
目前来看,上述群体对OpenAI禁令的影响都不大。
随着国内模厂的模型基本完善,不用再通过调用API的方式收集数据。海外应用的开发,应用往往需要对本地市场的深入了解,因此国内开发者数量规模也较小。相比之下,“套壳API”的初创公司可能受到的打击是最大的,不过通过“搬家”切换到国产大模型,快速找到能力接近的替代方案,也能一定程度上规避风险。
(no changes made as the content cannot be reasonably paraphrased)

所以总体来说,OpenAI更严格的API限制,并不会给中国AI行业带来很大的动荡。这是因为中国的人工智能技术和应用正在快速发展,且在很多方面已经形成了自己的技术生态系统和市场环境。因此,OpenAI的这些限制措施虽然可能会对某些具体应用产生影响,但不会对整个中国AI行业的发展产生根本性的冲击。
但这并不意味着,中国人工智能可以高枕无忧了。从“英伟达禁令”到“OpenAI禁令”,发出了一个鲜明的信号:“潘多拉魔盒”一旦开启,就不会关上,针对中国人工智能的封锁,也不可能在短时间内被撤回。
是时候摒弃“枪口抬高一寸”的侥幸心理和幻想了,事实证明,枪口随时可以朝下扣动扳机。
认清现实:不可逆的AI封锁
还有哪些牌可以出?
在封锁烈度上,美国官方和AI企业的行动在不断加强;在封锁广度上,从高性能AI芯片的底层算力,到大模型的底层算法,“釜底抽薪式”的封锁正逐渐延伸到AI基础设施的各个关键部分。
原文已经是中文内容,不需要进行进一步的扩写。
那么,在算力禁运、算法禁用之后,海外想要阻隔中国AI的发展,还有哪些牌可以打?梳理一下AI软件基础设施:
1. **数据资源限制**:数据是AI发展的核心,限制中国企业获取关键数据资源将直接影响AI的训练和应用。
2. **技术交流禁令**:阻止技术和知识的交流,特别是限制高级算法和工程师的合作,有助于减缓中国AI技术的进步。
3. **标准和认证壁垒**:通过设置严格的技术标准和认证要求,使中国企业难以进入国际市场,减少其全球影响力。
4. **知识产权保护**:加强对AI相关技术的知识产权保护,防止中国企业通过逆向工程等方式获取先进技术。
5. **资本市场制约**:限制中国企业在国际资本市场上的融资和投资,影响其技术研发和市场扩张能力。
6. **国际合作限制**:阻止或限制中国与其他国家在AI领域的合作,减少其技术交流和共同研发的机会。1. 框架。深度学习框架,是支持AI算法模型开发和部署的软件平台,对AI应用的开发效率和性能有重要影响。目前国内深度学习框架市场主要由飞桨(由百度开发)、TensorFlow(由Google开发)、PyTorch(由Meta开发)三家主导,共同占据了超过80%的市场份额。这三家均为开源框架,允许开发者自由地查看、修改和使用其源代码,不过TensorFlow、PyTorch作为开源平台也需要遵守所在国法律法规,并可以通过开源许可证等方式,限制开发者的访问。
The original HTML structure has been preserved as requested.

2.算子库。包含各种数学和逻辑运算函数的库,在深度学习框架中扮演着至关重要的角色,为各种算法提供了基础的计算单元。如果算子库是闭源的,又归属于海外公司,那么可以直接限制使用。开源的算子库也要遵循一定的开源协议,协议中往往会规定代码的使用、修改和分发规则,如果开发者没有获得适当的许可或权限,也无法使用。目前,国内飞桨、昇思等AI开发平台都发布了算子库。
3.数据集。AI界有句名言“garbage in,garbage out(垃圾进,垃圾出)”,高质量的数据集,对于AI算法模型的性能至关重要,在大模型时代也不例外。各个领域和应用场景都有专有数据集,比如计算机视觉领域的MNIST、CIFAR、ImageNet等。NLP领域的SQuAD、GLUE等,再比如AI蛋白质结构预测任务所需要的数据集,如CASP、AlphaFold DB、PDB等,这些数据集为AI研究提供了丰富的数据资源,大多由海外研究机构建立。
近年来,中国人工智能领域的高质量数据集也在快速建设,数据治理体系也在持续完善,数据作为核心生产要素的战略地位不断提升。但现阶段,与海外一流水平还存在差距。而人工智能算法的特别之处在于,不像传统软件能够一次性开发完成,模型需要持续学习、迭代和进化,依赖于持续更新的数据集进行训练。一旦数据集被限制访问,就如同剥夺了模型成长的土壤,甚至可能导致停滞不前。
此外还有编译器、集成开发环境(IDE)等,这些软件工具可以显著提高开发者的编程效率。如果被禁用,开发者将需要手动完成这些工作,从而导致开发效率降低,团队协作困难,甚至影响项目的进度和质量。

“英伟达禁令”执行以后,一位国内某计算厂商向脑极体表示,“虽然我们还可以使用特供版的AI芯片,但确实支持不了英伟达最新的平台了”。
所以说,硬件、软件基础设施共同构成了人工智能产业的支撑体系。面对阻碍中国人工智能发展的封锁禁令,一定要有“底线思维”,软件并不比硬件更安全,开源软件并不比闭源软件更安全。
准备应对
中国人工智能,必须同时具备理论研究和实际应用能力
提到国产化替代,总有人担忧这是在闭门造车、与世界脱节。AI作为高度全球化的高新技术产业,这种担忧确实不无道理。
但也必须看到,“没有一次AI断链是我们先动的手”。
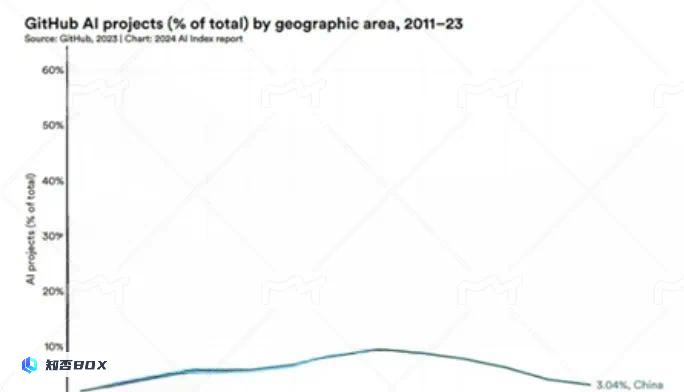
实际上,中国人工智能产学界始终保持着开放心态,积极吸收国际先进技术,与世界接轨。斯坦福大学发布的《2024年人工智能指数报告》显示,自2011年以来,GitHub上的开源人工智能项目,中国参与度不断增长,直到2019年在科技领域遭受不合理打压之后,才开始走低。
无论是芯片禁运,还是API禁用,都是海外以“国家安全”“保证美国AI领先地位”等理由,发起的单方面阻隔。而在短时间内,这种单方面动手的“AI封锁”,并不会告一段落。
这种情况下,中国人工智能将面临一个重要选择:是完全依赖国内自主研发,使用自主开发的底层软硬件?还是继续参与全球人工智能市场,更多地利用国外技术?
小孩子才做选择,成年人全都要。中国人工智能,必须学会“两条腿走路”。
第一条腿,是基础软硬件的自主创新,做好全栈人工智能技术国产化的准备。
中国AI在底层软硬件的关键“卡脖子”环节,都积累了不少力量。以软件为例,百度、华为云等头部大模型厂商,都建立了“AI大底座”,从底层算力(百度昆仑、华为昇腾)、基础模型、深度学习框架(飞桨、昇思)、全栈AI开发工具平台(千帆平台、昇腾AI云服务)等。
这些全栈自研的人工智能软硬件基础设施,可以让中国人工智能做好“最坏的准备”,无惧来自海外的断链风险。
但正如经济学家江小涓所说的,在当今科技全球化、产业全球化的格局下,“会做的全部自己做”并不是最优选项。

所以中国人工智能的第二支柱是保持与全球最新趋势的紧密联系,确保信息通畅、创新同步。
还记得芯片禁运之时,有网友义愤填膺地表示要“对等制裁”“不用也没有损失”,但一位资深从业者却说“别人小心眼,我们自己不能小心眼”。美国封闭但我们不能封闭,不能自己把路走窄了。
紧密贴近全球趋势、充分利用全球资源,是中国人工智能保持领先的必要条件。一方面,吸收全球最先进的技术,中国人工智能可以在更高的起点上推动技术自主创新,避免产业链割裂带来方向迷失,错过主流的人工智能发展机会。
另一方面,中国人工智能在科技竞赛中名列全球前茅,这种领先优势至关重要,不容忽视,必须与全球创新步调一致,因此需要积极拥抱国际市场和科技合作。
随着国产算力的突破,中国在人工智能领域的技术实力取得了显著进展。过去由于“英伟达禁令”,中国的AI技术和研究受到了很大的制约,但现在随着国产算力技术的不断突破,这种制约已不再对AI算力的发展造成障碍。在大家认为中国AI领域已经迎来了稳定发展的良好局面时,OpenAI却突然发布了新的禁令,这一举动犹如一道闪电,彻底打破了中国AI界对“限AI=限卡”的简单化幻想。
国产算力固然是底气所在,但绝非高枕无忧的保证,来自OpenAI的API限制说明,海外AI软件也并不完全可靠,同理,开源软件也并非绝对安全的屏障。

AI产业链封锁,如同悬在头顶的达摩克利斯之剑。但换个角度看,逐渐加码的禁令,恰恰是之前的措施劳而无功,没能起到彻底阻拦中国AI进步的效果,这也间接反映出中国AI产业的生存活力,是不会轻易被阻隔在世界之外的。
中国人工智能,只有正视现实,将每一个产业链的重要环节牢牢掌握在自己手中,才能持续留在全球市场的竞争桌上。
