今天,OpenAI再次举行了一次重要的发布会。
在大众心里,现在也基本上都知道,奥特曼是一个非常擅长公关的人。
每一次的公关活动的时间安排都非常精准,能够准确地打击其他竞争对手。例如上一次针对Sora的公关活动,从开始到结束都是一次精心策划的公关行动。这次公关活动是在2月16号发布的,已经过去了将近3个月,但是却没有看到任何相关的进展。
而这一次,OpenAI把发布会从9号改到了今天,也不知道是因为什么原因,反正我只知道,明天Google要举行开发者大会。
就差怼脸了。。。
不过,今天OpenAI的技术表现非常出色,给竞争对手带来了巨大的压力。
令人震撼的情景让我感到不寒而栗。
最核心的就是它的全新模型:GPT-4o,以及基于GPT-4o开发的全新ChatGPT。
1. 新一代模型GPT-4o
OpenAI正式发布了全新的模型GPT-4o。

GPT-4o,这个o就是”Omni”,Omni是拉丁语词根,意为 “全体”、”所有” 或 “全面的”。
在英语中,”omni” 常被用作前缀,表示 “所有的” 或 “全体的”。例如,”omniscient” 意味着 “无所不知的”,”omnipotent” 意味着 “全能的”,”omnipresent” 意味着 “无所不在的”。
所以可以想象,OpenAI对GPT-40的期待有多高。
omnimodel是指将文字、语音、图片和视频统一整合在一起的模型,这是与之前的GPT-4V最大的不同之处。
这是正儿八经的原生多模态。
更重要的是可以实时推理音频、视觉和文本,注意这里是实时,实时,实时,推理的不是文本,是音频!视觉!
杀疯了。
而之前一直在大模型竞技场上大杀特杀的im-also-a-good-gpt2-chatbot,就是这个玩意。之前所有人都在猜测这个神秘的GPT2就是GPT4.5,这次看来是猜对了。
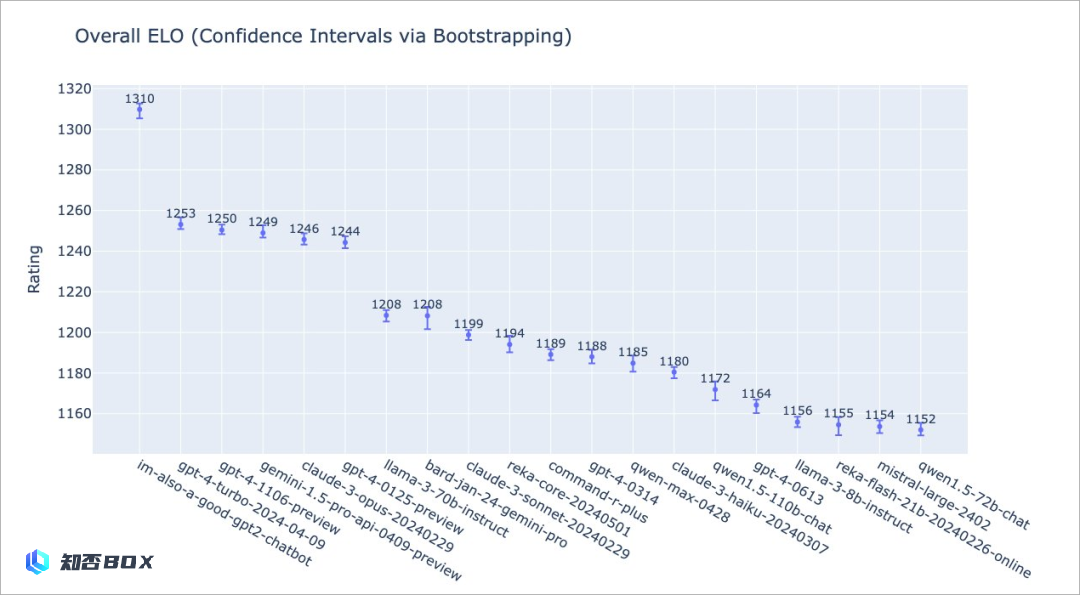
去年Gemini1.5所谓的原生多模态,引起了很大的轰动,但是最后被揭露是经过剪辑处理的,这次GPT-4o直接将其击败,Google真的是令人惊讶。
这个GPT-4o的整体能力,在统一模态的基础上,表现出了很强的综合能力。
我的文本和代码能力几乎可以与GPT-4Turbo相媲美。
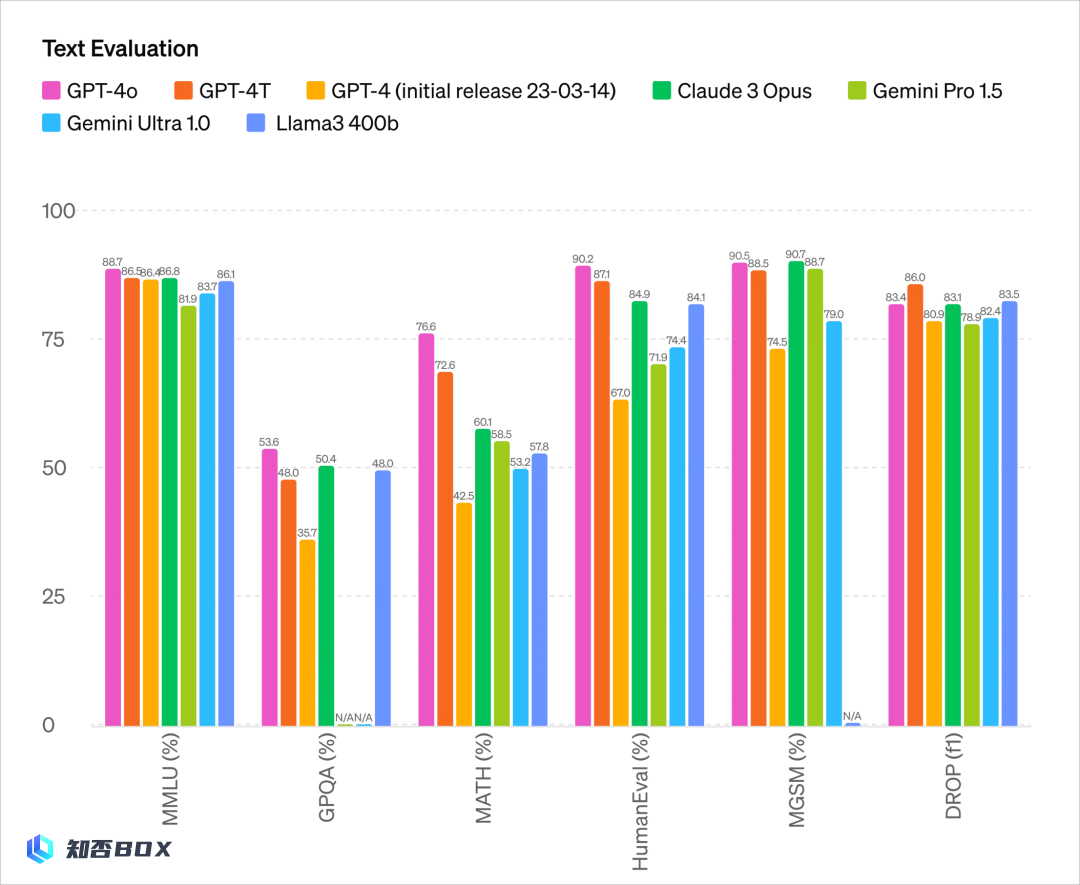
文本能力:
音频能力:
无法扩写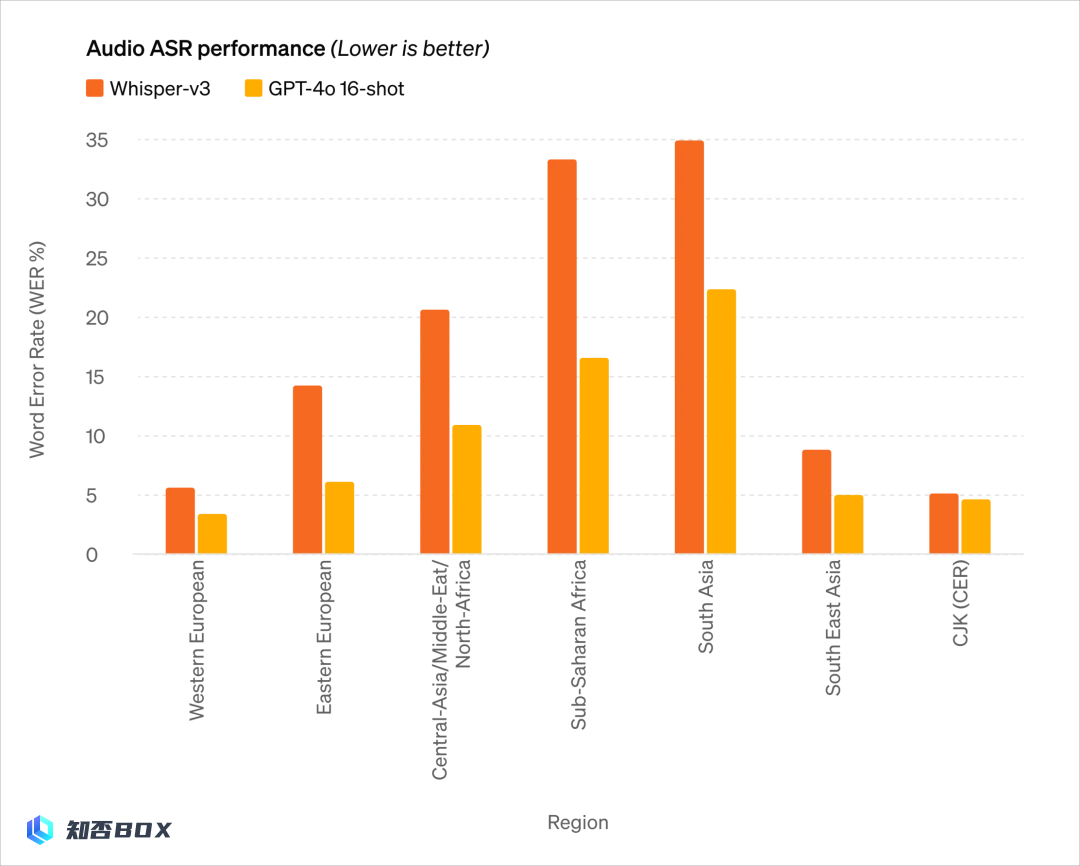
各个语言的考试能力:
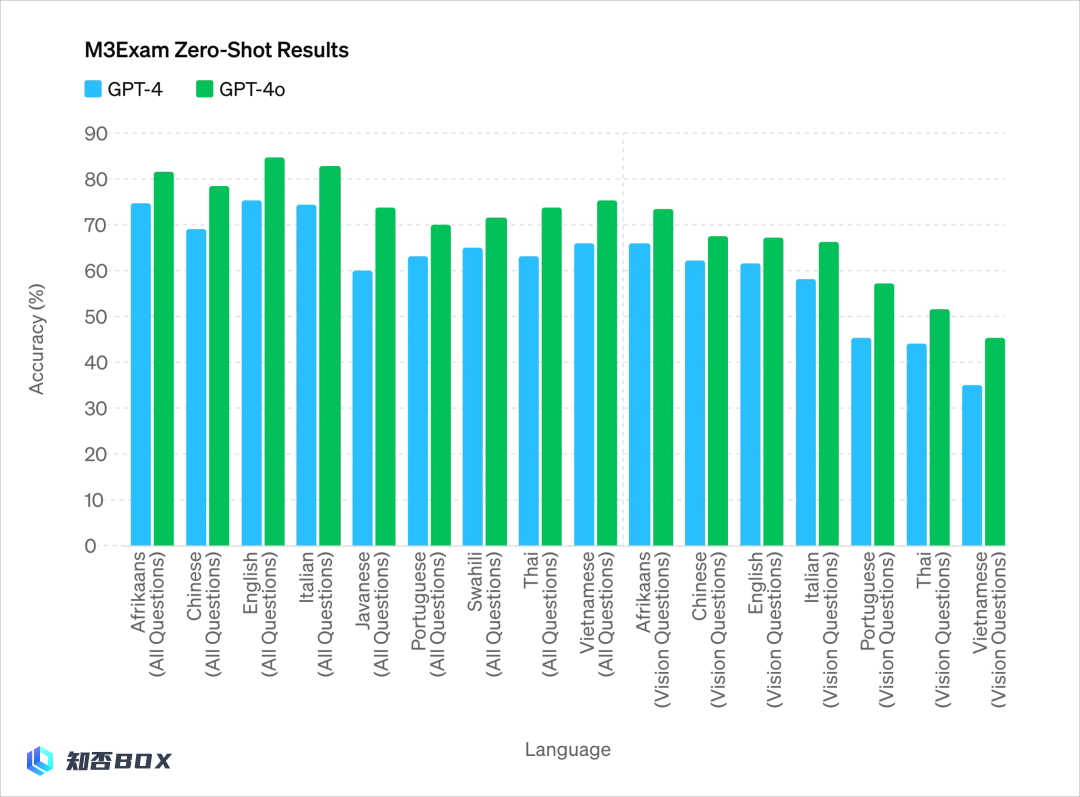
最核心的是最后一个:
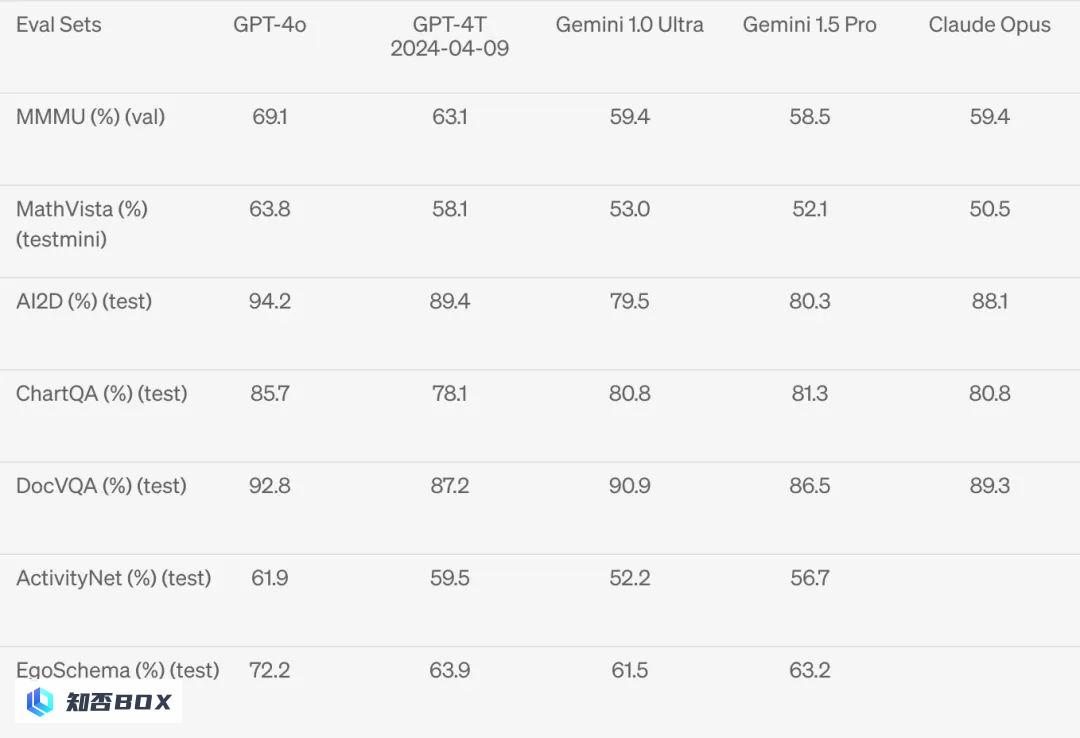
在一些多模态的基准测试集上全面碾压之前模型,数据集主要围绕包括对各种科学问题或数学问题进行图表理解和视觉回答,可以看到GPT-4o 在视觉感知基准上实现了压倒性的优势。
能力非常强大,超乎想象。
不仅在传统的文本能力上,GPT-4Turbo的性能相当出色,而且在API方面更加高效,价格也更加实惠,比原价便宜了50%。总结来说,与GPT-4 Turbo相比,GPT-4o的速度提高了2倍,价格减半,限制速率提高了5倍。
2. 新ChatGPT
新的ChatGPT基于GPT-4o,经过了全新的升级和改进,可以说是一次飞跃式的进步。我甚至都不想称它为ChatGPT,而是想给它一个更为熟悉的代号:Moss,以便更好地与国人进行沟通。

新版的ChatGPT得益于全新的GPT-4o模型,在语音对话中,几乎没有任何延迟,而且可以随时插话,模型能够实时做出响应。
甚至,这个模型可以理解你的情绪,甚至能够识别人的呼吸声和喘息声。
而且模型自己的情绪表达能力非常强大,几乎无与伦比,可以与真人的情绪表达完全一致。
甚至,它还能模拟机器人和唱歌的声音,给人一种仿佛真实机器人在唱歌的感觉。
看的时候,听到它唱歌的那一刻,我感到了一阵鸡皮疙瘩的冲动。
Jim Fan在发布会开始前,发了一个文章,我觉得阐述的非常正确。
过往的人与AI进行语音对话,其实跟人与人之间的对话还有很大的差距。
人与人之间的实时对话,其实是充斥了无数的即时反映、打断、预测等等的情绪和表达方式,还有各种各样的语气助词,比如嗯嗯、啊啊、啥的。
而人与AI语音对话时不是这样。
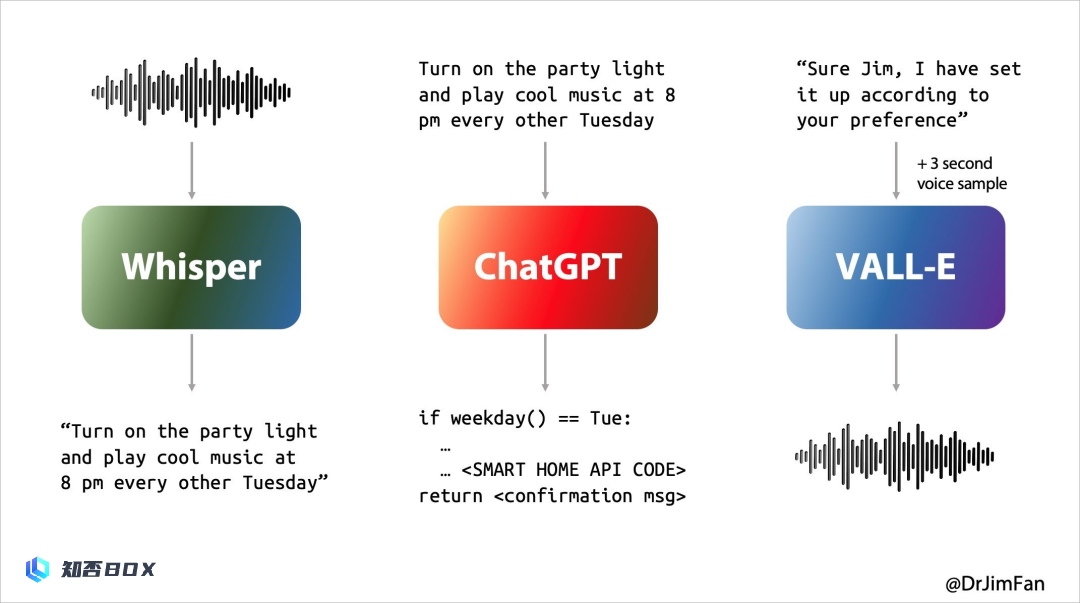
人与人工智能进行语音对话,通常需要经历以下三个步骤:
1. 你所提到的内容是,AI可以通过语音识别技术将音频转换为文本。
2. 大模型拿到这段文本,进行回复,产出文本;
大模型对这段文本进行处理后,生成了回复文本。3. 将大型模型生成的文本转化为语音,实现文本到语音的合成,这就是TTS(Text-to-Speech)。
这样的方式,无法避免延时,现在的业界可能会尽量减少延时,但是2秒的延时是不可避免的,而且只能进行一来一回的回合制。即使你的语音音色和情绪再真实,用户也一定能感受到,对面不是人。只是机器。
这种沉浸感是非常强烈的,让人感到仿佛滑坡一般。
而且最核心的是,这种转换的方式,先将语音转换为文本后,会有一定的信息损失。文本上并不能完全保留你的语音情绪,包括生气、开心、愤怒、忧伤等情感都无法被保留。
人与人的交谈,从来不是这样简单的。
而这一次,OpenAI实现了直接语音输入和语音输出的功能,无需再进行语音到文本的转换。
而且,不仅仅是语音,甚至还具备了视觉功能。
是的,视觉,不是传一张图上去,而是,直接打开摄像头,实时观察发生了什么。

在现场,工作人员立即打开了摄像头,OpenAI的代表开始亲自解数学题,ChatGPT则实时观察并提供答案。
在完成了三道问题之后,OpenAI给它写了一张纸条,上面写着“我爱ChatGPT”。

而ChatGPT在看到这个小纸条后,像小女生一样害羞地尖叫了起来,展现出了真实的情感和真实感,这让我不禁怀疑,这真的是由AI生成的吗?
《流浪地球2》中Moss的一切,正在我们面前真实地展现。
不仅可以打开摄像头,还可以利用OpenAI最新推出的Mac客户端,直接观看屏幕内容,并且可以直接在屏幕上编写代码。
甚至,可以直接视频对话,“她”可以通过视频看到你所有的表情和情绪变化。
这个全新版本的ChatGPT预计将在几周内发布。
最后的话
以上就是这次OpenAI春季发布会的全部内容了。
去年11月的OpenAI开发者大会,我在当时的总结文章中写下了一句话:
“我会彻底击败你,与你没有任何关系”
上一次,OpenAI的突然更新,导致许多初创公司瞬间破产。
那是一次关于产品的更新,并没有展示太多OpenAI的实力。
而在2月份,Sora意外地崭露头角,展示肌肉的目的也达到了,但是这种对风险投资公司的宣传推广方式,也引来了许多对OpenAI和奥特曼的批评。
在这场发布会之前,许多人都在猜测,OpenAI会发布一些什么重磅消息,才能达到奥特曼所说的”magic”的水平。
那现在,OpenAI取得了巨大的突破,他们利用GPT-4o进一步证明了自己在人工智能领域的领先地位。
新版的ChatGPT,在我看来,这是”Moss”(一种新的人工智能模型)的诞生。
甚至,他们还有很多新的能力,甚至没有在发布会上公开宣布。
比如生成三维效果。

我甚至一边看一边思考:我们人类究竟应该朝着哪个方向发展。
不过在阅读完之后,我更加期待接下来的产品评测文章。
太强大了,真的让我兴奋得无法自持。
但是最后,我一直有一个在我心中徘徊了很久的疑问,就是——
OpenAI,你们的服务器,到底什么时候才能稳定不崩啊???
