四月我们迎来了人工智能芯片三连发!
4月9日,Intel在Vision 2024活动中发布了全新一代的Gaudi 3 AI芯片。与此同时,Google Cloud在Cloud Next 2024大会上首次公开了专为数据中心设计的首款Arm架构CPU──Google Axion。紧接着的第二天,即4月11日,Meta官方发文展示了他们全新自研的AI芯片MTIA。
在这三款产品中,Intel新一代Gaudi 3与NVIDIA H100展开直接竞争。在AI模型算力方面,Gaudi3 AI芯片的模型训练速度和推理速度都更加出色,分别提升了40%和50%,平均性能提升达到了50%,能效也提高了40%。更重要的是,Gaudi3 AI芯片的成本比H100更低,性能更强,价格更实惠。
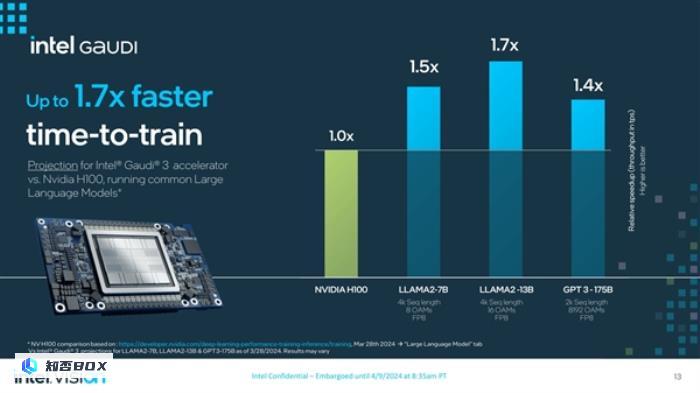
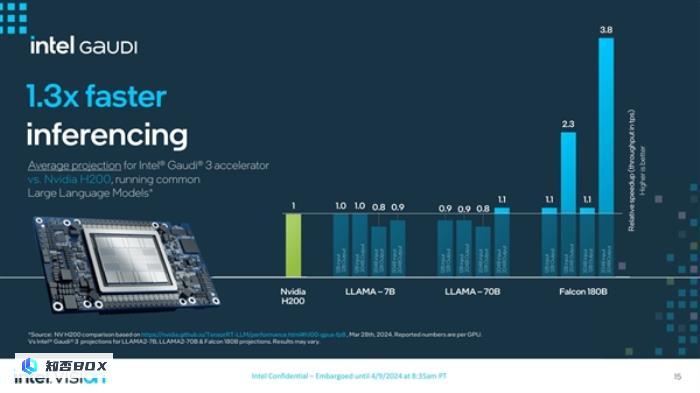
根据官方公布的数据显示,Gaudi 3在面对NVIDIA的H200 GPU时表现出色。在LLAMA-7B以及LLAMA-70B的某些场景中,与H200相比,性能差距基本在10%以内。
Intel在Vision 2024上也同时介绍了这款芯片的生产节点,计划在今年第三季度向客户发货Gaudi 3 AI芯片。包括联想、惠普、Dell和Supermicro等OEM厂商都将使用这款新品来构建系统。
然而,尽管加上AMD的Instinct MI300,Gaudi 3仍然很难动摇NVIDIA在AI新领域的领先地位。
根据美银分析师Vivek Arya的研究报告,预计到2024年,英伟达的AI加速器市场占有率将超过75%。而定制化芯片(如Google TPU、亚马逊Trainium/Inferentia加速器、微软Maia)的市场占有率将为10~15%。剩下的10~15%市场份额将由AMD、英特尔以及其他未上市企业分享。
尽管目前定制化芯片市场份额不高,但几乎所有服务商都在加快开发各类芯片产品,Google也不例外。

在9日举行的Cloud Next 2024大会上,Google Cloud首度公开专为数据中心设计的首款Arm架构CPU──Google Axion,相较目前最新一代的同等x86架构执行个体,效能最高提升50%、能源效率最高提升60%。
在9日举行的Cloud Next 2024大会上,Google Cloud首次公开了专为数据中心设计的首款Arm架构CPU──Google Axion。与目前最新一代的同等x86架构执行个体相比,Google Axion的效能最高提升了50%,能源效率最高提升了60%。Axion CPU正在支持YouTube广告、Google Earth Engine等多项Google服务。Google Cloud表示,Axion基于开放架构设计,使用Arm技术的客户可以轻松采用,无需进行应用程序重构。
Google Cloud客户可在旗下Compute Engine、Kubernetes Engine、Dataproc、Dataflow、Cloud Batch等云服务中使用Axion CPU。Google Cloud计划于今年稍晚时间向客户开放Axion CPU的使用。
Google Cloud客户可以在其旗下的多个云服务中使用Axion CPU,包括Compute Engine、Kubernetes Engine、Dataproc、Dataflow和Cloud Batch等。Google Cloud计划在今年晚些时候向客户开放Axion CPU的使用。
此外,Google Cloud还推出了下一代AI加速器TPU v5p。单个TPU v5p Pod包含8,960个芯片,是上一代TPU v4 Pod的两倍以上。
TPU v5p主要用于训练规模最大、要求最高的生成式AI模型。Google Cloud不会直接销售Axion CPU和TPU v5p芯片给个人用户,而是将其作为云服务提供给企业客户使用。这样做的目的是减少对英特尔、NVIDIA等外部供应商的依赖,并且能够更好地优化硬件以满足自家业务的特定需求,从而为客户提供更具竞争力的云计算和AI服务。
相比Google在AI算力方面具有的规模,Meta的资源相对较少。不过,Meta在AI领域的投入也相当丰富。此前有报道称,Meta一次性购买了35万枚NVIDIA H100 GPU,每张售价数万美元,这极大地提升了其AI算力水平,为Meta在人工通用智能(AGI)领域的研发提供了强大支撑。
Meta计划将其计算基础设施升级为“相当于近60万张H100的算力”。除了购买GPU之外,自研硬件也是另一种选择。Meta基础设施副总裁Alexis Bjorlin表示,通过自研硬件,公司可以控制整个技术栈,从数据中心设计到训练框架,这种垂直整合是实现AI研究突破的关键。
去年五月,Meta公司宣布推出了第一代AI推理加速器MTIA v1。而最近,他们又发布了下一代产品。新款MTIA芯片采用了5nm工艺,相比之前的版本,它拥有更多的处理核心,并且功耗也从25W提升到了90W。此外,时钟频率也从800MHz提高到了1.35GHz。
Meta表示目前已经在16个数据中心使用新款MTIA芯片,与MTIA v1相比,整体性能提高了3倍。但Meta表示,这个提升是通过测试两种芯片的 “四个关键模型” 的性能表现得出的。
据Meta官方介绍,新一代MTIA(Meta Tensor Inference Accelerator)的设计理念在于寻求计算、内存带宽和内存容量三者之间的理想平衡。这一改进不仅优化了芯片的性能,更使得推理任务的执行变得更为顺畅。
科技大厂自主研发定制化芯片的原因有两方面。一方面,定制化芯片可以与自身需求高度匹配,从而提高性能和效率。另一方面,自研芯片也考虑到了安全性和经济性的因素。以NVIDIA H100为例,该芯片不仅售价昂贵,而且还存在产能不足的问题。然而,AI的发展对于强大的算力支持有着极高的依赖性。
因此,越来越多的科技巨头开始内部开发芯片。Meta公司正在加入亚马逊AWS、微软和谷歌母公司Alphabet的行列,希望减少对昂贵芯片的依赖。
然而,这并未对行业对NVIDIA AI加速器的巨大需求产生显著影响。在人工智能的热潮下,NVIDIA成为世界第三大科技公司,仅次于微软和苹果公司。
根据2024财年的数据,该数据中心运营商的销售额总计475亿美元,比前一年的150亿美元增长了很多。分析师预测,这个数字在2025财年将会再次翻倍,这将进一步巩固该公司在未来几年的市场地位。
人工智能(AI)正在改变个人电脑(PC)处理器的升级重点
AI技术的迅猛发展不仅改变了服务器端芯片的走向,也正在深刻影响个人电脑(PC)处理器的发展。自苹果M系列芯片率先集成神经网络处理单元(NPU)以来,其他厂商也纷纷跟进。
AMD从锐龙7000系列笔记本处理器中开始加入神经处理单元(NPU)。而英特尔则在推出”AI PC”的概念时,明确将NPU作为硬性指标之一。
NPU(神经网络处理器)是专门为人工智能和机器学习场景进行优化设计的处理器。与通用的CPU和GPU相比,NPU在硬件结构上进行了针对性的优化,专注于高效执行神经网络推理等与人工智能相关的计算任务。

在过去几十年中,个人电脑处理器的发展一直以提升中央处理器(CPU)性能为主要目标。然而,在人工智能时代,各种人工智能技术的迅猛发展迫使芯片制造商不得不在人工智能能力方面加大投入。微软推出的Windows Copilot等人工智能功能对个人电脑芯片的人工智能性能提出了更高的要求。

为了满足这一需求,AMD计划在即将推出的Strix Point APU上大幅增强神经处理单元(NPU)的性能,甚至牺牲了部分中央处理单元(CPU)和图形处理单元(GPU)的缓存空间。而英特尔在Arrow Lake、Lunar Lake和Panther Lake等新一代芯片中也投入了大量资源,致力于提升NPU的算力,分别达到约35 TOPS、105 TOPS和140 TOPS。

从这段文字中可以看出,人工智能(AI)在个人电脑(PC)领域正逐渐成为芯片厂商的新的竞争焦点。神经处理单元(NPU)正在从辅助性能转变为核心功能,未来可能成为PC处理器升级的重点,取代传统的中央处理器(CPU)和图形处理器(GPU)在性能上的优先地位。这一趋势反映了人工智能正在深刻改变着个人电脑生态系统的技术架构。
SoC(System on a Chip)是当前的大势所趋
南京邮电大学(NPU)的加入也在影响芯片设计制造方式,SoC(System-on-Chip)在手机行业中已经变得非常普遍,现在,这种集成设计的理念也开始渗透到个人电脑芯片的设计中,
SoC(系统级芯片)设计的优势在于可以将中央处理器(CPU)、图形处理器(GPU)、神经网络处理器(NPU)等各种功能单元集成在一个芯片上,使内存和处理器能够更加紧密地集成,从而提高数据传输速度和整体系统性能。这正如苹果M系列芯片所展现的优势:通过紧密集成内存,可以显著提升内存带宽。

Intel的Core Ultra和AMD的Ryzen 8000系列处理器都采用了SoC(System on a Chip)设计,这意味着它们将多种功能单元集成到一个芯片上。这些功能单元包括CPU(中央处理器)、GPU(图形处理器)和NPU(神经网络处理器),它们的集成进一步提升了处理器的性能。此外,这些处理器还与板载内存直接连接,使得数据传输更加高效,进一步提升了系统性能。
然而,就桌面PC而言,SoC设计在某些方面存在一些限制。台式机处理器通常需要更强的升级性能,而SoC结构不利于后续硬件的升级。因此,Intel和AMD在笔记本芯片上采用了SoC和传统处理器+芯片组的双线并进策略,以满足不同市场需求。
