5 月 26 日消息,微软近日公布了旗下小语言 AI 模型家族(SLM)最新成员“Phi-3-vision”,这款模型主打“视觉能力”,能够理解图文内容,同时据称可以在移动平台上流畅高效运行。
微软近日公布了旗下小语言 AI 模型家族(SLM)最新成员“Phi-3-vision”,这款模型主要注重提升视觉能力,能够对图文内容进行理解。据称,该模型在移动平台上的运行效果非常流畅高效。据介绍,Phi-3-vision 是微软 Phi-3 家族首款多模态模型,该模型的文字理解能力基于 Phi-3-mini,同时也具备 Phi-3-mini 的轻量特点,能够在移动平台 / 嵌入终端中运行;该模型参数量为 42 亿(4.2十亿),大于 Phi-3-mini(3.8B),但小于 Phi-3-small(7B),上下文长度为 128k token,训练期间为 2024 年 2 月至 4 月。

注意到,Phi-3-vision 模型的最大特色正如其名,主要支持“图文识别能力”,号称能够理解现实世界的图片含义,还能快速识别提取图片中的文字。
微软表示,Phi-3-vision 特别适合办公场合,开发人员特别优化了该模型在识别图表和方块图 (Block diagram) 方面的理解能力,据称可以利用用户输入的信息进行推论,同时还能做出一系列结论,为企业提供战略建议,号称“效果比肩大模型”。
在模型训练方面,微软声称 Phi-3-vision 是通过训练多种类型的图片和文字数据而得到的。这些数据包括经过严选的公开内容,例如教科书等级的教育材料、代码、图文标注数据、现实世界知识、图表图片、聊天格式等内容,以确保模型输入内容的多样性。微软还强调他们在使用训练数据时注重隐私保护,所使用的数据是可追溯的,并不包含任何个人信息。
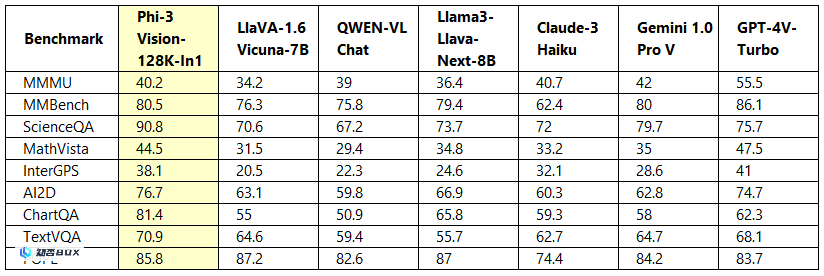
性能方面,微软提供了Phi-3-vision模型,与字节跳动的Llama3-Llava-Next(8B)模型、微软研究院和威斯康星大学、哥伦比亚大学合作的LlaVA-1.6(7B)模型、阿里巴巴通义千问QWEN-VL-Chat模型等竞品模型进行了比较。比较图表显示,Phi-3-vision模型在多个项目上表现出色。