过去一年,中国大型经济模型一直被贴上「追赶美国」的标签,但近日,推特上却有人曝出:
美国斯坦福大学的一个人工智能团队被怀疑抄袭、复制了一家中国大型模型公司的开源成果,他们的模型架构和代码完全一样。这一事件被雷峰网报道。
舆论已经开始发酵,引起了圈内人士的广泛讨论。雷峰网
根据AI科技评论整理,事情的经过大致如下:
5 月 29 日,斯坦福大学的一个研究团队发布了一个名为「Llama3V」的模型,声称只需 500 美元(约合人民币 3650 元)就能训练出一个最先进的多模态模型(SOTA),并且其效果可以与 GPT-4V、Gemini Ultra 和Claude Opus 相媲美。
Github开源:https://github.com/mustafaaljadery/llama3v
HuggingFace开源:https://huggingface.co/mustafaaljadery/llama3v(已删库)
Medium发布文章:https://aksh-garg.medium.com/llama-3v-building-an-open-source-gpt-4v-competitor-in-under-500-7dd8f1f6c9ee
Twitter官宣模型:https://twitter.com/AkshGarg03/status/1795545445516931355
由于该团队的作者(Mustafa Aljaddery、Aksh Garg、Siddharth Sharma)来自斯坦福大学,他们还拥有特斯拉、SpaceX、亚马逊和牛津大学等知名机构的相关背景经历,因此该模型发布的推特帖子迅速获得了超过30万的浏览量,并被转发了300多次。这一成绩使得该模型迅速登上了Hugging Face的首页。
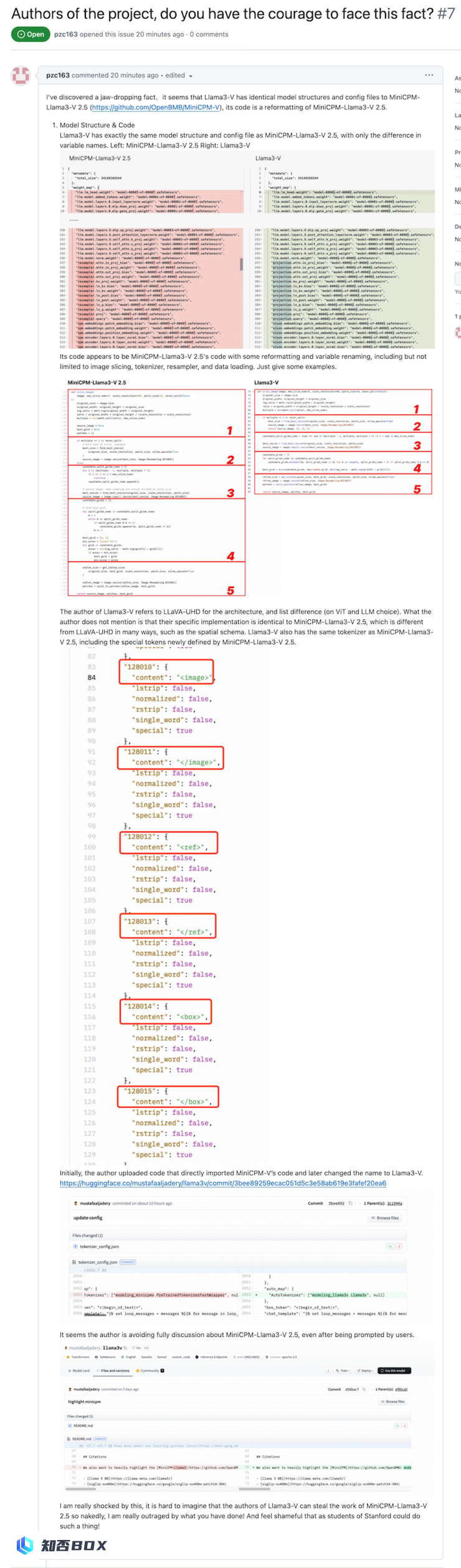
但很快,没过几天,推特与 Hugging Face 上就开始出现怀疑的声音,质疑 Llama3V 套壳面壁智能在 5 月中旬发布的 8B 多模态小模型 MiniCPM-Llama3-V 2.5,且没有在 Llama3V 的工作中表达任何「致敬」或「感谢」 MiniCPM-Llama3-V 2.5 的声音。
对此,Llama3V 团队回复,他们表示他们只是使用了 MiniCPM-Llama3-V 2.5 的分词器,并声称他们在 MiniCPM-Llama3-V 2.5 发布之前就开始了这项工作。
接下来,就在6月2日,有一些网友在Llama3V的Github项目下提出了一些事实性的质疑。然而,这些质疑很快就被Llama3V团队删除了。因此,那些提出质疑的网友感到非常愤怒,他们决定去MiniCPM-V的Github页面上还原事件,并提醒面壁智能团队关注这件事情。
随后,面壁团队通过测试 ,发现 Llama3V 与 MiniCPM-Llama3-V 2.5 在「胎记」般案例上的表现完全相同,「不仅正确的地方一模一样,连错误的地方也一模一样」。
至此,推特舆论开始发酵,「斯坦福抄袭中国大模型」一事迅速传播开来。
1、「套壳」证据确凿,斯坦福团队无法辩驳
最开始,用户对Llama3V套壳MiniCPM-Llama3-V 2.5开源模型的真实性提出了质疑。然而,Llama3V的作者团队并没有承认这一点,而是声称他们只是使用了MiniCPM-Llama3-V 2.5的tokenizer,并声称他们在MiniCPM-Llama3-V 2.5发布之前就开始了这项工作。
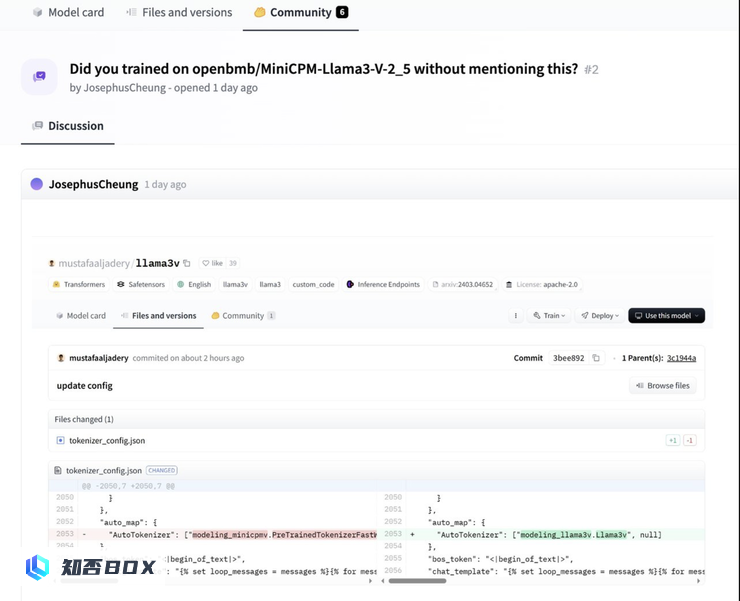
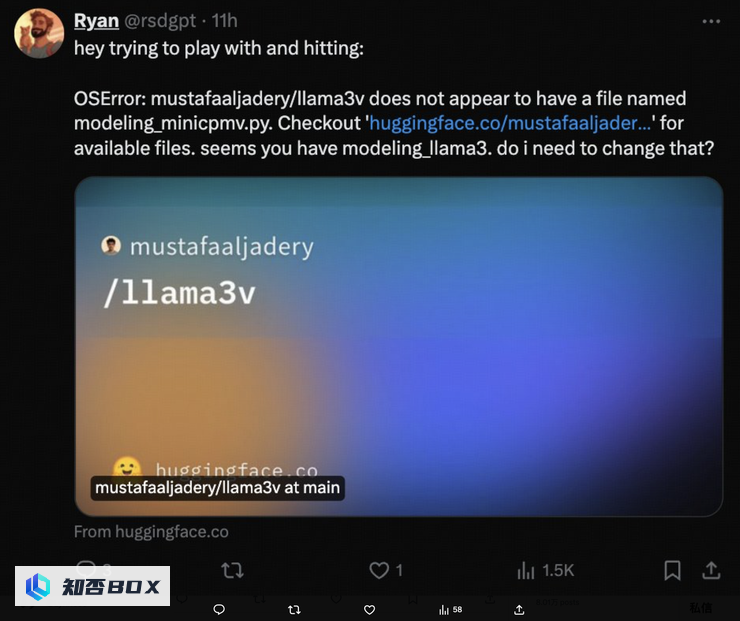
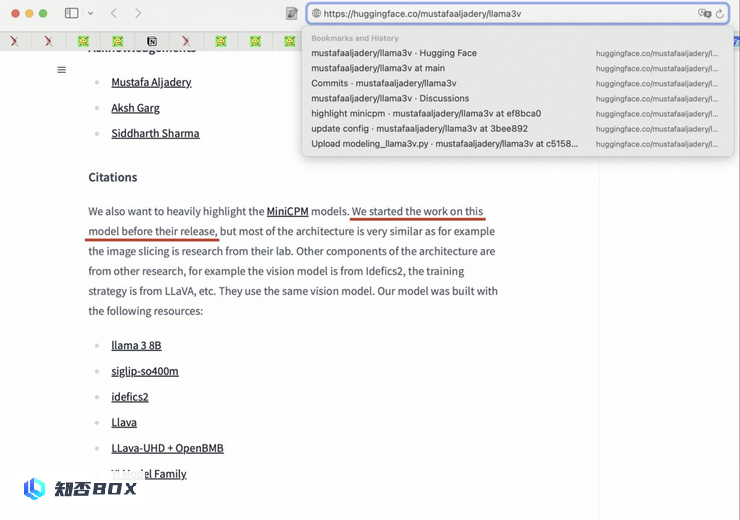
然而,一些善意的网友对Llama3V作者团队的回应表示怀疑,并在Llama3V的Github Issue上发布了一系列质疑。他们列举了4个具体的证据,但很快被Llama3V团队删除。幸运的是,作者事先截图保存了这些证据:
面对网友的质疑,Llama3V 作者只是回复说他们只是使用了 MiniCPM 的配置来解决 Llama3V 的推理 bug,并表示「MiniCPM 的架构是来自 Idéfics,SigLIP也来自 Idéfics,他们也只是追随 Idéfics 的工作」而不是 MiniCPM 的工作,因为「MiniCPM 的视觉部分也是来自 Idéfics 的」——
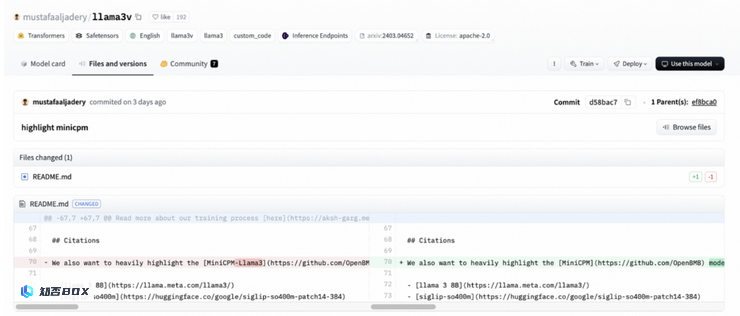
并且将原来 readme 里引用致谢「MiniCPM-Llama3」改为了「致谢MiniCPM」:
但根据网友的复盘、梳理,Llama3V 并非只是简单的借鉴,而是有 4 点证据能充分表明其「套壳」了 MiniCPM-Llama3-V 2.5。
但根据网友的复盘、梳理,Llama3V 并非只是简单的借鉴,而是有 4 点证据能充分表明其「套壳」了 MiniCPM-Llama3-V 2.5。根据网友的复盘和梳理,我们可以得出结论,Llama3V并不仅仅是简单地借鉴了MiniCPM-Llama3-V 2.5,而是通过4个证据充分表明了它的「套壳」行为。
证据 1:
Llama3V 项目采用了与 MiniCPM-Llama3-V 2.5 项目完全相同的模型结构和代码实现。
Llama3-V 的模型结构和配置文件与 MiniCPM-Llama3-V 2.5 完全相同,只是变量名不同。
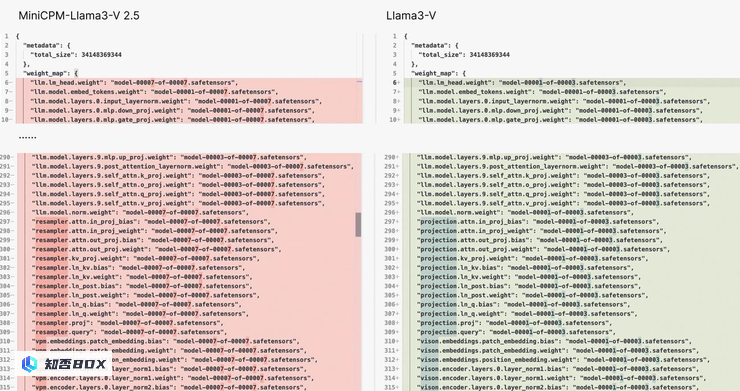
图左为 MiniCPM-Llama3-V 2.5,图右为 Llama3V
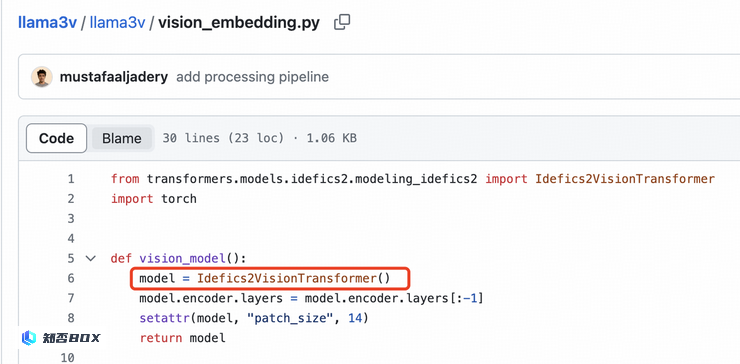
Llama3-V 的代码是通过对 MiniCPM-Llama3-V 2.5 的代码进行格式调整和变量重命名得到的,包括但不限于图像切片方式、tokenizer、重采样器和数据加载。

证据 2:
Llama3V 团队声称他们在架构上引用了 LLaVA-UHD,但实际上 Llama3V 与 MiniCPM-Llama3-V 2.5 的结构完全相同。然而,在空间模式等多个方面,Llama3V 与 LLaVA-UHD 之间存在较大的差异。
Llama3-V 具有与 MiniCPM-Llama3V 2.5 相同的标记器(tokenizer),包括 MiniCPM-Llama3-V 2.5 新定义的特殊标记:
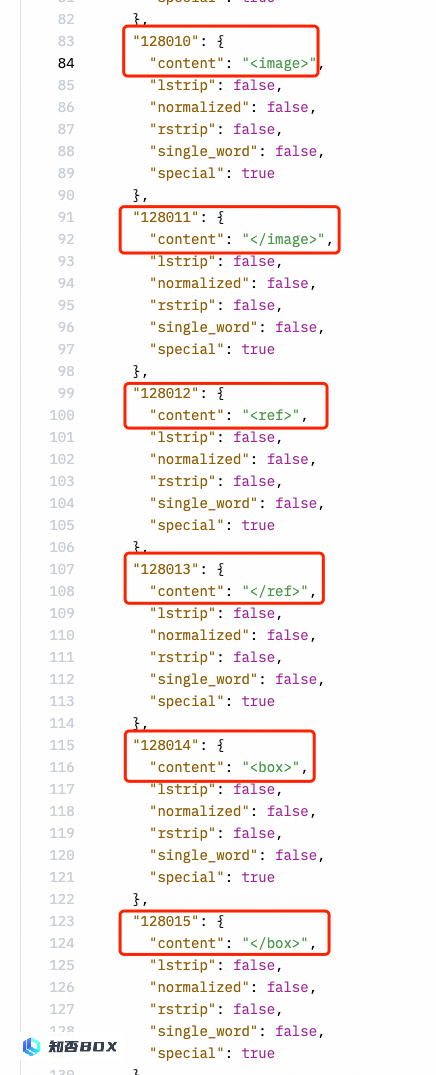
证据 3:
Llama3V 作者曾在 Hugging Face 平台上直接导入了 MiniCPM-V 的代码,后来将其改名为 Llama3V。然而,当事件曝光后,AI 科技评论访问 Hugging Face 页面时却发现该页面已经显示为「404」。
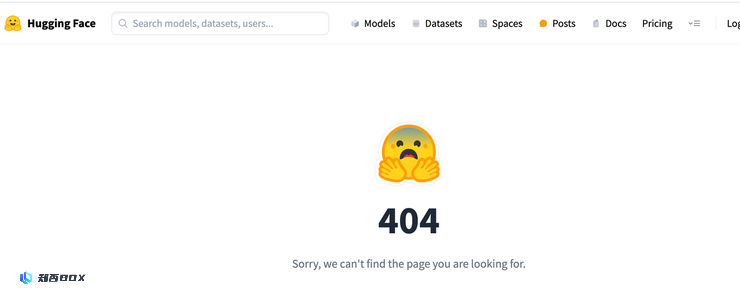
https://huggingface.co/mustafaaljadery/llama3v/commit/3bee89259ecac051d5c3e58ab619e3fafef20ea6Llama3V
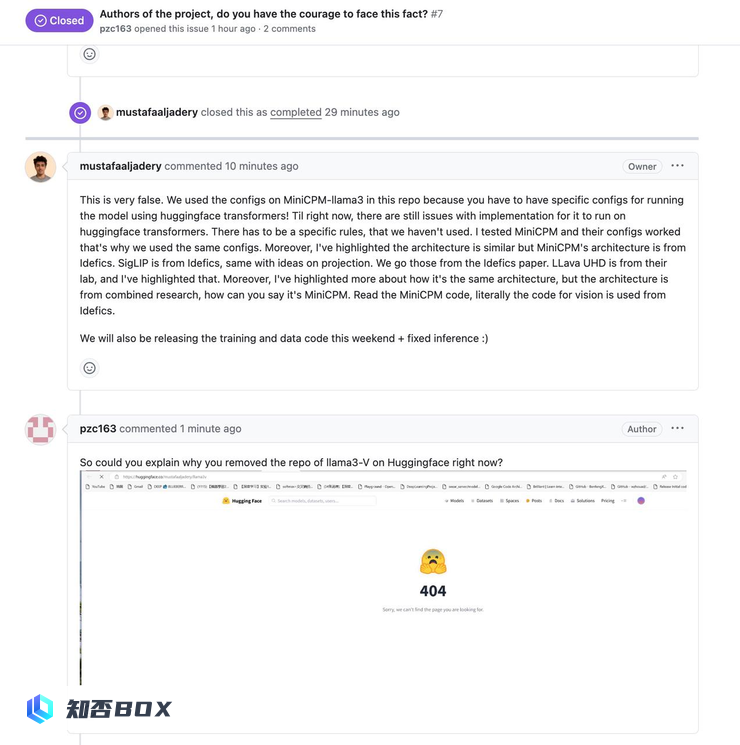
据作者回应,他们删除 Hugging Face 仓库的原因是为了修复模型的推理问题。他们还提到他们尝试使用 MiniCPM-Llama3 的配置,但最终并没有使用。
戏剧效果十分强烈,该网友随后贴出了如何使用 MiniCPM-Llama3-V 的代码,详细介绍了运行 Llama3V 模型推理的步骤。
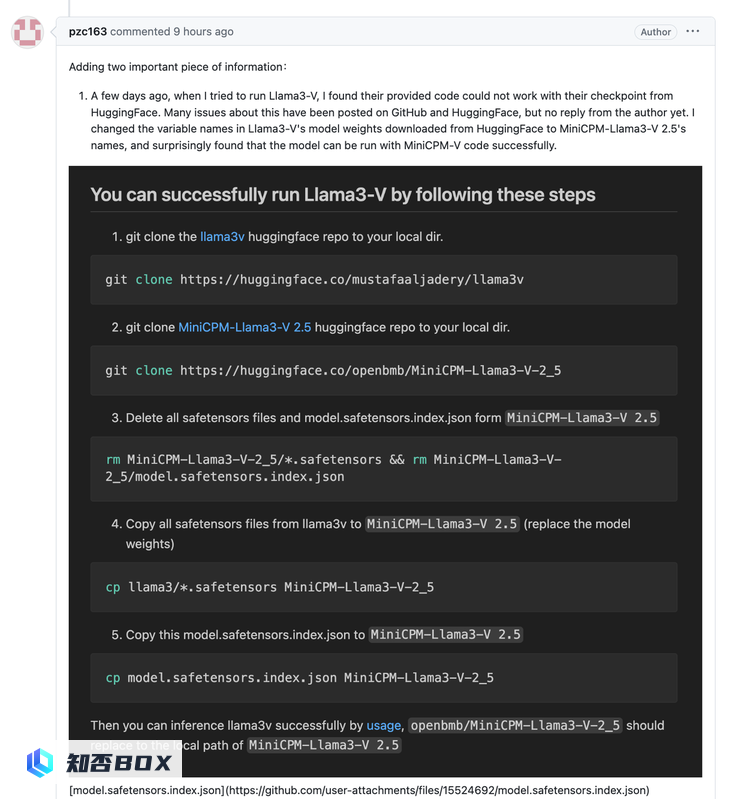
当 Llama3V 的作者被询问如何能在 MinicPM-Llama3-V2.5 发布之前就使用它的 tokenizer 时(因为其一开始称他们在 MinicPM-Llama3-V2.5 发布前就已经开始了 Llama3V 的研究),Llama3V 的作者开始撒谎,称是从已经发布的上一代 MinicPM-V-2 项目里拿的 tokenizer:
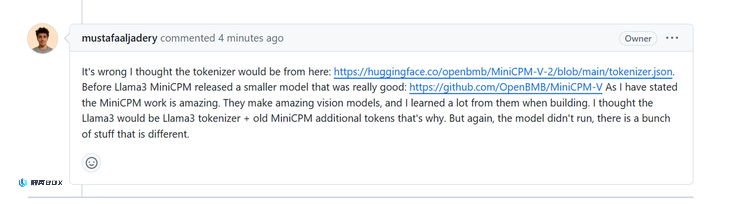
但事实是,根据AI科技评论向面壁团队了解,MiniCPM-V-2的tokenizer与MinicPM-Llama3-V2.5完全不同。在Huggingface中,它们是两个不同的文件,不仅仅是同一个tokenizer文件,而且文件大小也完全不同。
MinicPM-Llama3-v2.5 的 tokenizer 是由 Llama3 的 tokenizer 和 MiniCPM-V 系列模型的一些特殊 token 组成的。MiniCPM-v2 在 Llama3 开源之前就发布,因此不包含 Llama3 的 tokenizer。
证据 4:
Llama3V 的作者删除了 GitHub 上的相关 issue,并似乎对 MinicPM-Llama3-V2.5 的架构或 Llama3V 自己的代码不太了解。
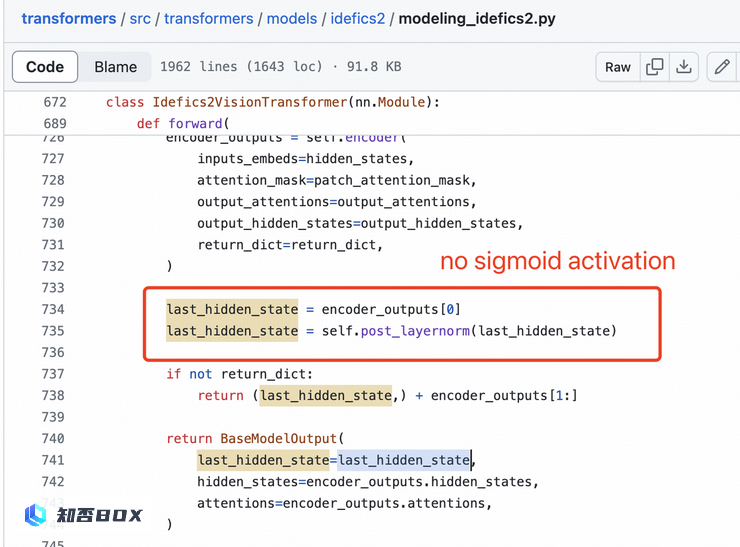
Perceiver重采样器是一个单层的交叉注意力机制,而不是两层自注意力机制。SigLIP 的 Sigmoid 激活函数并未用于训练多模态大型语言模型,而仅用于 SigLIP 的预训练。
但 Llama3V 在论文中的介绍却说其采用了两层自注意力机制:

而 MiniCPM-Llama3-V 2.5 和 Llama3V 代码如下,体现的却是单层交叉注意力机制:
Llama3-V:
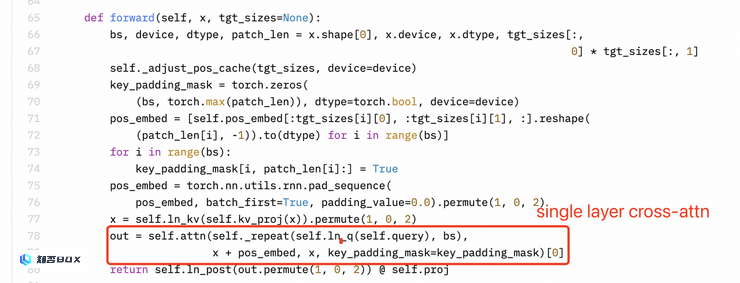
MiniCPM-Llama3-V 2.5:
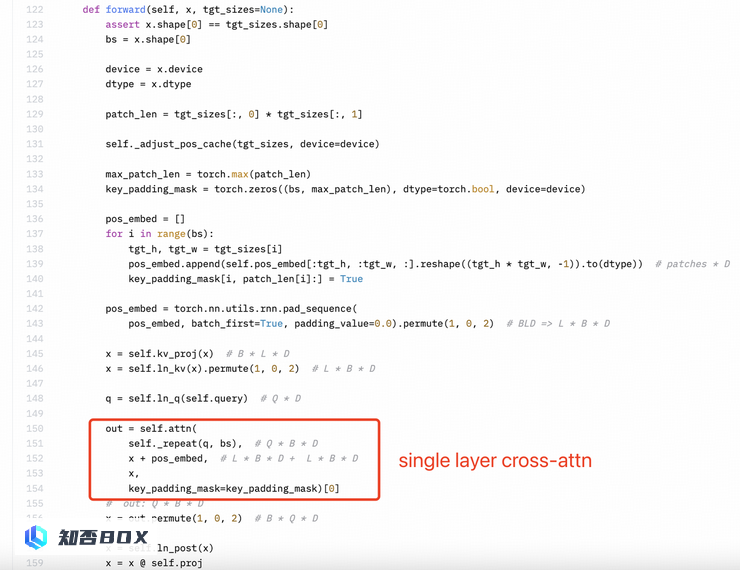
此外,视觉特征提取过程中不需要使用sigmoid激活函数:

2、推特舆论发酵,面壁回应
6 月 2 日下午,该事件开始在推特上发酵,MiniCPM-V 的作者亲自发帖,表示「震惊」,因为斯坦福的 Llama3V 模型居然也能识别「清华简」,这一发现令人惊讶。
据 AI 科技评论向面壁团队了解,「清华简」是清华大学于 2008 年 7 月收藏的一批战国时期的竹简的简称;识别清华简是 MiniCPM-V 的「胎记」特征。该训练数据的采集和标注均由面壁智能和清华大学自然语言处理实验室团队内部完成,相关数据尚未对外公开。
斯坦福大学的Llama3V模型在与MiniCPM-Llama3-V 2.5检查点的加噪版本进行比较时表现出了高度相似的特点。
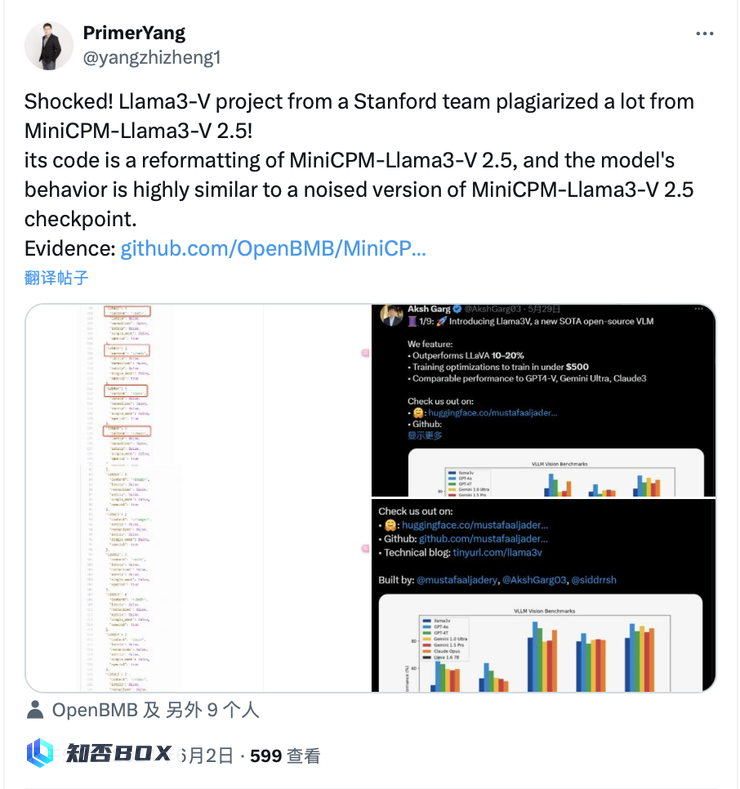
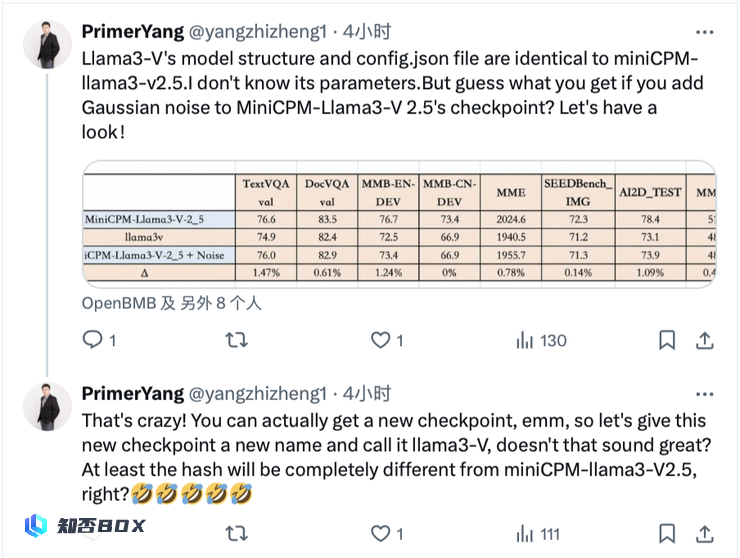
以下是面壁团队成果与 Llama3V 对「清华简」的识别结果进行对比。结果显示,两个模型在正确的地方完全一致,错误的地方也完全相同:

问题:请识别图像中的竹简字?
MiniCPM-Llama3-V 2.5:民
Llama3-V:民
GT:民
错误识别示例:

问题:请识别图像中的竹简字?
MiniCPM-Llama3-V 2.5:君子
Llama3-V:君子(指品德高尚、行为端正的人)
GT:甬(甬为甬江的简称)
以下是在1000个清华简字体上的识别效果:
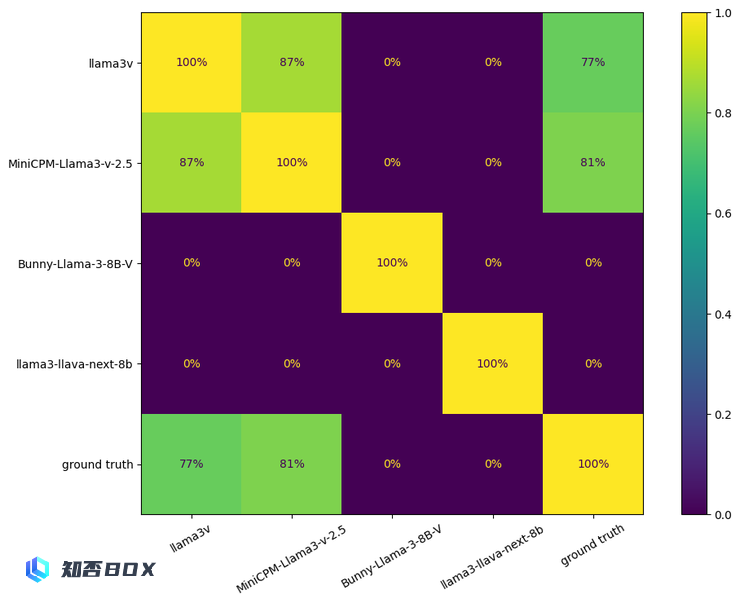
可以看到,Llama3V 与 MiniCPM-Llama3-V 2.5 的重叠部分占比高达 87%,且两个模型的错误分布很相似:Llama3V 的错误率为 236,MiniCPM-Llama3-V 2.5 的错误率是 194,两个模型在 182 个错误识别上达成了一致。
同时,两个模型在清华简上的高斯噪声也具有相似的特征:
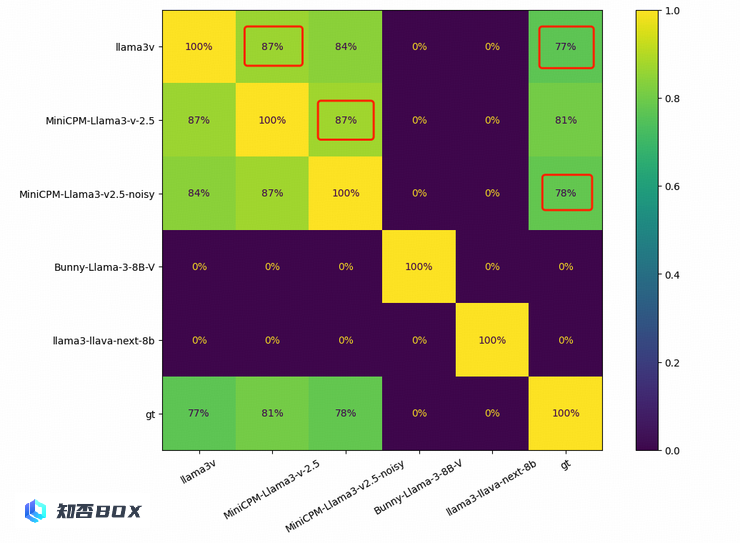
此外,Llama3V 的 OCR 识别能力在中文字上也与 MiniCPM-Llama3-V 2.5 高度相似。对此,面壁团队表示,他们很好奇斯坦福团队是如何只用「500 美元就能训练出这么高深的模型性能」。
根据公开信息显示,Llama3V 的两位作者 Siddharth Sharma 与 Aksh Garg 是斯坦福大学计算机系的本科生,他们在机器学习领域发表过多篇论文。
其中,Siddharth Sharma 曾在牛津大学进行学术交流、在亚马逊公司进行实习;Aksh Garg 也曾在 SpaceX 公司进行实习。
这件事反映出,人工智能研究的投机分子不分国界。
同时,这也表明中国科研团队在开源大模型方面的实力已经超越国界,引起了越来越多国际知名机构和开发者的关注和学习。
中国大型机构不仅在追赶世界顶尖机构,也正在成为被世界顶尖机构学习的榜样。
由此可见,今后看客们审视国内外的大模型技术实力对比,应该多一份民族自信、少一点崇洋媚外,将关注度多聚焦在国内的原创技术上。
最后,一句话总结:投机不可取,永追求创新。
