
埃隆·马斯克掌控的那几家公司——包括 SpaceX、特斯拉、xAI 乃至 X(原 Twitter)——都需要大量的 GPU,而且也都是为自己的特定 AI 或者高性能计算(HPC)项目服务。但问题在于,市场上根本就没有充足的 GPU 能够满足他们各自宏伟目标所承载的勃勃野心。为此,马斯克必须为自己所能得到的有限 GPU 规划出最优用途。
原文已经是中文且内容完整,无需进一步扩写。
筹集资金比筹集图形处理器(GPU)容易得多
早在 2015 年,马斯克就以敏锐的眼光成为 OpenAI 的联合创始人。而在 2018 年的一场权力斗争之后(我们猜测这场斗争很可能与推动人工智能模型所需的巨额资金有关,以及对这些模型治理思路的影响),马斯克离开了 OpenAI,为微软提供了机会。这家软件巨头投入了大量资金,并迅速促使 OpenAI 成为生产级生成式人工智能的主要力量。面对这样的现实,马斯克在 2023 年 4 月果断成立了 xAI 公司,此后该初创公司一直在积极筹集资金并争取 GPU 配额,旨在建立能够与 OpenAI、微软、谷歌、亚马逊云科技、Anthropic 等知名巨头竞争的计算基础设施。
而其中,筹集资金显然是最简单的部分。
截至 5 月底,安德烈森·霍洛维茨(Andreessen Horowitz)、红杉资本(Sequoia Capital)、富达管理(Fidelity Management)、Lightspeed Venture Partners、Tribe Capital、Valor Equity Partners、Vy Capital 和 Kingdom Holding(沙特王室控股公司)纷纷加入 xAI 总额 60 亿美元的 B 轮融资,一举推动其融资总值来到 64 亿美元。这是个好的开始,更幸运的是马斯克从特斯拉的全球经营中拿到了 450 亿美元的薪酬收益,因此可以随时把这笔巨款投入到 xAI GPU 的后续发展身上。(当然,更明智的作法应该是保留一部分作为特斯拉、X 和 SpaceX 的 GPU 采购基金。)
从某种角度来看,特斯拉实际上相当于一次性支付了马斯克在2022年4月购买X所投入的全部440亿美元,并额外给了他10亿美元。这笔资金足以用作备用资金购买2.4万个GPU集群。必须承认,作为电动汽车的先驱力量,特斯拉已经颠覆了整个汽车行业,其2023年的销售额达到968亿美元,净利润为150亿美元,公司目前持有的现金为291亿美元。然而,即使在当今财富分配极不公平的时代,这种450亿美元的回报仍然是一个相当离谱的薪酬方案。但是,考虑到马斯克有着自己要完成的重大使命,他领导的董事会愿意牺牲特斯拉的利益,投入更多资本来讨好这位时代的骄子。
不过按照同样的市值逻辑来判断,我们似乎也可以用 6500 亿美元买下摩根大通,而资金来源仍然是美国银行、阿布扎比、美联储以及我们能说动的其他资方。这样到了明年,我们就能给自己开出比收购成本略高一点点的薪酬——比如说 6750 亿美元。这样还清贷款之后,咱还能剩下 250 亿美元随便花花……抱歉跑题了,但这种情景真是想想都让人开心。
总之从目前的情况看,xAI 必须在计算、存储和网络层面表现出强劲的需求。
Grok-0 大语言模型拥有 330 亿个参数,是在 xAI 成立几周之后就于 2023 年 8 月开始训练。Grok-1 拥有可响应提示词的对话式 AI 功能,有着 3140 亿参数,于 2023 年 11 月上市。该模型随后于 2024 年 3 月开源,很快 Grok-1.5 模型也正式亮相。与 Grok-1 相比,1.5 版本有着更长的上下文窗口和更高的认知测试平均绩点。
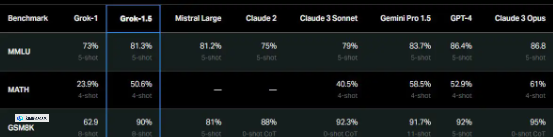
可以看到,Grok-1.5 的智能水平稍逊谷歌、OpenAI 和 Anthropic 等竞争对手开发的同类模型。
即将推出的 Grok-2 模型将在8月内与大家见面,该模型计划在24000张英伟达H100 GPU上进行训练。据报道,该模型采用的是甲骨文的云基础设施。(甲骨文已经与OpenAI签署一项协议,允许其使用xAI未能尽用的剩余GPU容量。)
马斯克曾在多条推文中表示,Grok-3 也将在今年年底问世,需要 10 万个英伟达 H100 GPU 集群上接受训练,并将能够与 OpenAI 和微软正在开发的下一代 GPT-5 模型相媲美。甲骨文和 xAI 也积极就 GPU 容量分配方式讨论协议。但三周前价值 100 亿美元的 GPU 集群交易破坏消息一出,马斯克当即决定转变方向,在田纳西州孟菲斯南部的一处旧伊莱克斯工厂建造起“计算超级工厂”,用以容纳他自有的 10 万个 GPU 集群。如果大家恰好身在孟菲斯周边,接下来的情况可能有点疯狂——因为 xAI 号称将占用 150 兆瓦的区域供电。
据彭博社的报道,目前该处工厂已经分配到 8 兆瓦供电,未来几个月内有望增加到 50 兆瓦。而要想继续超越这个数字,则需要经过田纳西河谷管理局的繁琐审批。
不过目前来看除非英伟达愿意全力协助,否则 马斯克似乎不太可能在今年 12 月之前拿到自己已订购的 10 万张 H100 GPU。
寻求英伟达这种芯片的公司名单很长,可能包括当今大多数大型科技公司,但只有少数几家公司公开宣称他们拥有多少 H100 芯片。
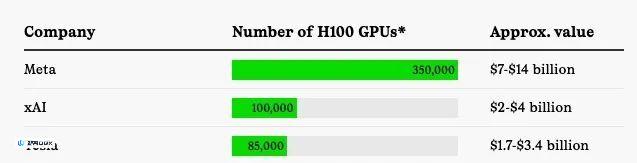
截图来源:The Information
据《The Information》报道,风险投资公司 Andreesen Horowitz 正囤积超过 2 万块昂贵的 GPU,作用是将其出租给人工智能初创公司以换取对方公司股份。
OpenAI 也一直没有透露他们拥有多少 H100 芯片,但据《The Information》报道,该公司以大幅折扣租用了微软提供的专用于训练的处理器集群,这是微软对 OpenAI 100 亿美元投资的一部分。据报道,这个训练集群的算力相当于 12 万块 Nvidia 上一代的 A100 GPU,并将在未来两年内花费 50 亿美元从 Oracle 租用更多的训练集群。
特斯拉一直在努力收集 H100。今年 4 月,马斯克在一次财报电话会议上表示,特斯拉希望在年底前拥有 3.5 万到 8.5 万块 H100。
为了帮助 xAI 筹集 GPU,马斯克最近还被特斯拉股东起诉,指控他将原本用于汽车制造商 AI 训练基础设施的 12,000 块 H100 芯片转给了 xAI。在昨天的特斯拉第二季度财报电话会议上,当被问及这一调配问题时,马斯克表示,这些 GPU 之所以被送往 xAI,是因为“特斯拉的数据中心已经满了,实际上没有地方可以放置它们。”
原文已经是中文,无法进行合理性的扩写。10 万张 H100 的单一集群,谁有能力构建出来?
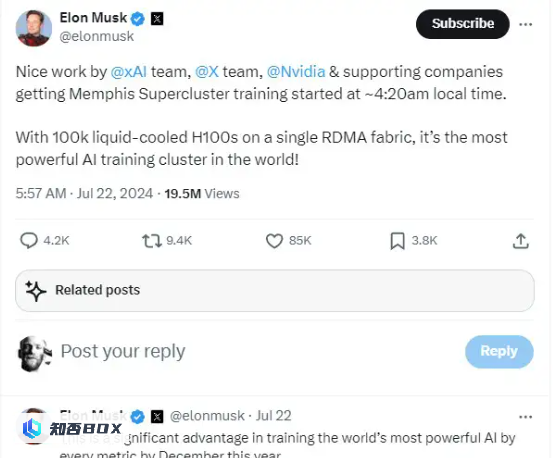
xAI、X、英伟达和各支持部门都表现出色,孟菲斯超级集群训练已于当地时间凌晨 4:20 启动。
其单一 RDMA 结构上承载有 100,000 张液冷 H100 GPU,这是全球最强大的人工智能训练集群!
要实现在今年 12 月之前训练出全球最强人工智能模型的目标,这一切无疑是个显著的优势。也许马斯克的这套系统最终会被称为超级集群,也就是 Meta Platforms 对于采购来、而非自建人工智能训练系统时指定的称呼。
另外 10 万张 GPU 这个结论恐怕只是个愿景,也许到 12 月时 xAI 能拿到的 GPU 总共也只有 2.5 万张。但即使是这样,此等规模仍足以训练出一套体量庞大的模型。我们看到的部分报告指出,孟菲斯超级集群要到 2025 年晚些时候才能最终完成扩展,按目前的 GPU 供应能力来说这话其实颇为合理。
另外,上线后,孟菲斯超级集群的供电也是一个问题,不过马斯克也并没有说到底启动了多少张 H100。有网友讽刺道,马斯克的这种说法在极端情况下确实是成立的,比如只启动了 1 个 GPU 进行训练,而其他 99,999 个 GPU 并没有足够的电源来连接。
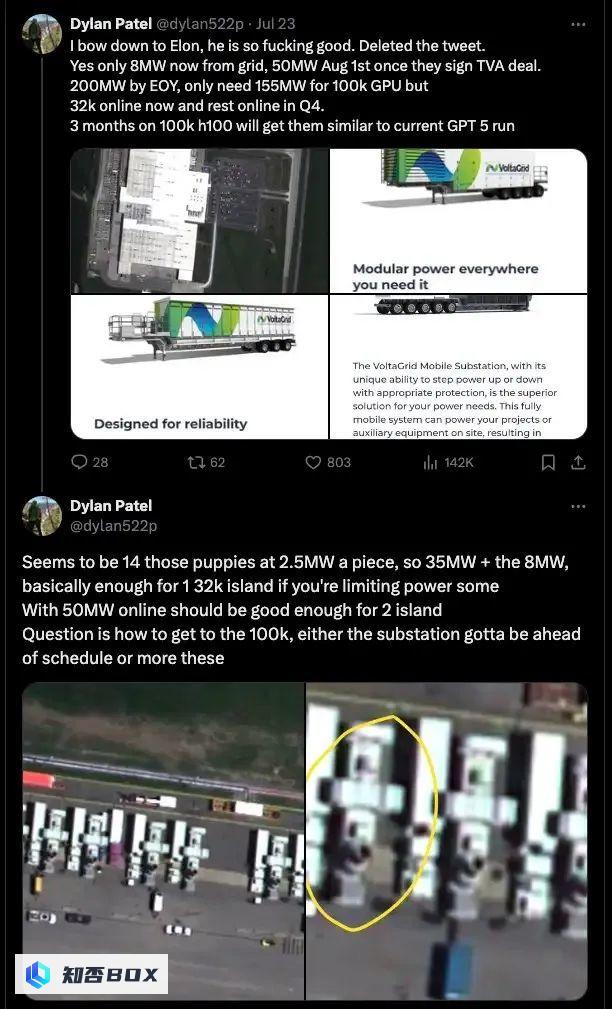
目前只有 3.2 万块上线,其余将在第四季度上线。如果达到 10 万块 GPU,要么变电站提前完工,要么需要更多这样的设备。
我们还可以从 Supermicro 公司创始人兼 CEO Charles Liang 的推文中做点推断,该公司正在负责为 xAI 孟菲斯数据中心部署水冷设备:

很高兴能与马斯克一同创造历史,与他的孟菲斯团队合作也是一段美好的经历!为了达成目标,我们必须尽可能完美、快速、高效且环保地推进工作——虽然需要付出很多努力,但也同样极具意义而且令人兴奋!

目前还不清楚关于服务器基础设施的具体信息,但我们强烈怀疑这套系统将采用八路 HGX GPU 基板,并且属于 Supermicro 的机架式系统,其设计灵活来自英伟达的 SuperPOD 配置方案,但同时又有独特的工程调整以降低价格水平。采用八路 HGX 基板,该系统总计可容纳 1.25 万个节点,后端网络将承载 10 万张 GPU 和 10 万个端点;前端网络同样拥有 1.25 万个端点,即用于访问集群中数据和管理类负载的节点。
瞻博网络首席执行官 Rami Rahim 也讨论了该公司参与孟菲斯超级集群项目的具体细节:
恭喜马斯克、xAI 和 X!很高兴瞻博网络成为孟菲斯超级集群团队中的一员,并将我们的网络解决方案融入到这项创新工程当中。
从这些推文的内容来看,瞻博方面似乎是以某种方式拿下了孟菲斯超级集群的网络交易。考虑到 Arista Networks 和英伟达也在人工智能集群网络方面拥有深厚积累,马斯克最终选择瞻博着实令人感到惊讶。我们还没有从 Arista 那里看到与孟菲斯项目有关的任何消息;但在 5 月 22 日,英伟达在发布其 2025 财年第一季度财报时,公司首席财务官 Colette Kress 曾经表示:
“今年第一季度,我们开始针对 AI 发布经过优化的全新 Spectrum-X 以太网网络解决方案。其中包括我们的 Spectrum-4 交换机、BlueField-3 DPU 和新的软件技术,用以克服以太网承载 AI 工作负载时面临的挑战,为 AI 处理提供 1.6 倍于传统以太网的网络性能。
Spectrum-X 的销量也在不断增长,吸引到众多客户,包括一个庞大的 10 万 GPU 集群项目。Spectrum-X 为英伟达网络开辟出了全新的市场,使得纯以太网数据中心也能够容纳大规模 AI 类负载。我们预计 Spectrum-X 将在未来一年内跃升为价值数十亿美元的产品线。”
首先需要承认一点,这个世界上肯定没有多少项目能够豪爽地叫出“10 万张 GPU”这么夸张的体量,所以英伟达在 5 月声明中提到的几乎必然就是孟菲斯超级集群。再结合最近马斯克对于该系统的评价,我们认为英伟达应该是依靠 Spectrum-X 设备拿下了后端(或者叫东西向)网络部分,而瞻博则负责实现前端(或者叫南北向)网络部分。Arista 那边则没有任何动静。
但截至目前,我们仍不清楚孟菲斯超级集群具体会使用哪种存储解决方案。其可能是基于 Supermicro 的闪存加硬盘混合型原始存储阵列,可运行任意数量的文件系统;也可能是 Vast Data 或者 Pure Storage 提供的全闪存阵列。但如果非要选出一种赢面最大的方案,那我们会大胆认为 Vast Data 应该是参与了这笔交易,并拿下规模可观的存储订单。不过这种猜测也没有明确的依据,只是根据该公司大规模存储阵列过去两年在高性能计算和 AI 领域表现出的市场吸引力提出的假设。
