两周前,我们发布了领先的开源大模型「Eurux-8x22B」。相比我们之前的作品Llama3-70B,这个模型发布时间更早,综合性能相当出色,尤其是在推理性能方面更加强大。我们刷新了开源大模型推理性能的SOTA,可以说是开源大模型中的「理科状元」。这个模型的激活参数仅为39B,支持处理64k上下文,相比Llama3速度更快,能够处理更长的文本。
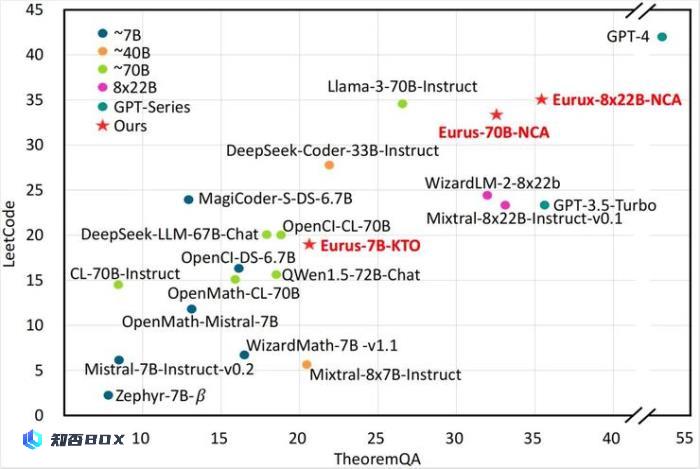
图注:面壁Eurux-8x22B 模型在 LeetCode 和 TheoremQA这两个具有挑战性的基准测试中,刷新开源大模型推理性能 SOTA(State-of-the-Art)。
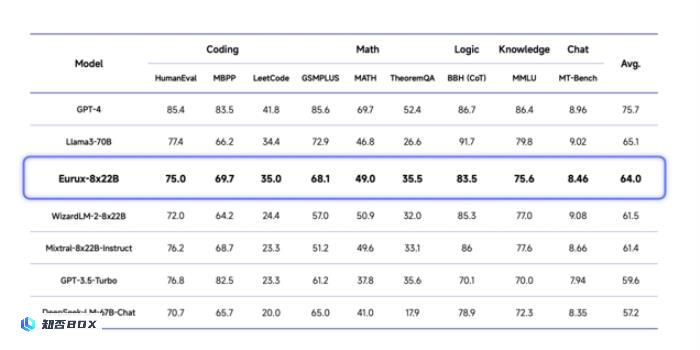
图注:面壁Eurux-8x22B 模型综合性能与 LlaMa3-70B 相当,超过了开源模型 WizardLM-2-8x22b, Mistral-8x22b-Instruct,DeepSeek-67b,以及闭源模型 GPT-3.5-turbo。
Eurux-8x22B 是由 Mistral-8x22B 对齐而来的。它具有强大的战斗力,这得益于面壁 Ultra 对齐技术的全新升级——UltraInterat 大规模、高质量对齐数据集。此前,面壁 Ultra 对齐系列数据集已经成功提升了全球超过200个大模型的性能,被誉为大模型上的分数提升神器。
Eurux-8x22B模型+对齐数据集,全家桶开源:
链接:https://huggingface.co/openbmb/Eurux-8x22b-nca
开源大模型「理科状元」开源大模型「理科状元」复杂推理能力是评估大型模型性能差异的关键能力之一,也是实际应用大型模型所必需的核心能力。
Eurux-8x22B在代码和数学等复杂推理的综合性能方面超越 Llama3-70B,刷新开源大模型 SOTA,堪称「理科状元」。特别在 LeetCode (180道LeetCode真题)和 TheoremQA(美国大学水准的STEM题目)这两个具有挑战性的基准测试中,超过现有开源模型。
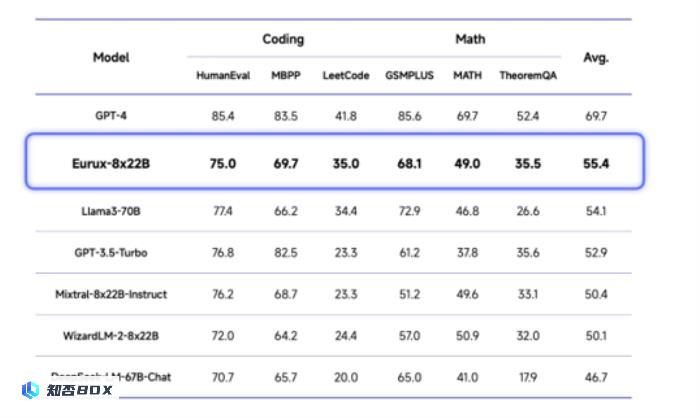
图注:Eurux-8x22B 在代码和数学等复杂推理综合性能方面超越 Llama3-70B,刷新开源大模型 State of the Art(SOTA)。
开源大模型「理科状元」Eurux-8x22B在实际应用中表现如何呢?
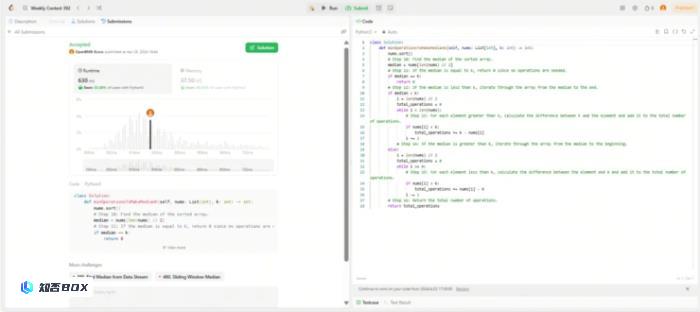
在最近的LeetCode周赛中,Eurux-8x22B在Python编程方面表现出色,超过了80%的参赛选手,成功解决了四道算法题中的三道。这个成绩使得他有望通过互联网大厂的程序员编程面试。
下面是本次周赛中Eurux-8x22B对一道中等难度的算法题的真实解答:

除了在编程方面具备出色的能力,Eurux-8x22B在解答数学题方面也是轻而易举的。
例如给它一道高中排列组合题,Eurux-8x22B 首先给出了清晰的解题思路,然后一步步地拆解执行,再进行结果汇总,最后得到正确答案。

再考察它一道代数题,Eurux-8x22B 直击要害,运用二项式定理,清晰简洁地给出了正确的解答。

接着给它一道向量代数题,Eurux-8x22B 也能轻松解答。

高考数学题可能是让很多人回忆起来就头疼的一类题目,但是Eurux-8x22B这款计算器可以准确地解答。
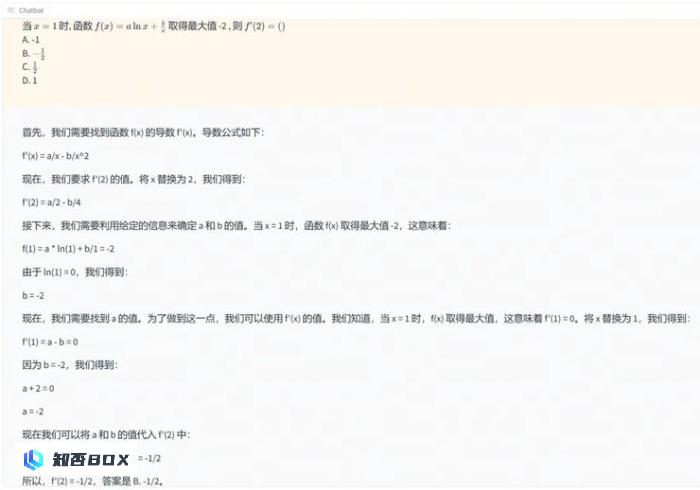
(需要说明的是,Eurux-8x22B 没有针对中文语料进行额外的微调和对齐!)
面壁 Ultra 对齐技术,大模型上分神器!本次大模型「理科状元」 Eurux-8x22B 的优异表现,得益于来自面壁 Ultra 对齐技术的大规模、高质量对齐数据集UltraInteract上新。
好数据,才有好模型。此前,面壁 Ultra 对齐技术已经“强壮”了全球超过200个大模型,堪称大模型上分神器。
➤UltraInterat对齐数据集地址:
?UltraInteract是一个专门设计用于提升大模型推理能力的大规模、高质量的对齐数据集。该数据集包含了覆盖数学、代码和逻辑推理问题的12个开源数据集的86K条指令和220K偏好对,总共约有五十万条数据。与之相比,LLaMA3-70B模型使用了千万量级的对齐数据,这从侧面证明了UltraInteract数据集的优质性,即数据质量胜过数据数量。UltraInteract数据集在开源后受到了社区的广泛好评。

从领先的端侧模型「小钢炮」MiniCPM,到开源模型推理新 SOTA 的Eurux-8x22B,为什么面壁智能总能推出同等参数、性能更优的「高效大模型」?答案是,大模型是一项系统工程,而面壁作为国内极少数兼具大模型算法与基础设施能力的团队,拥有自研的全流程高效生产线:面壁 Ultra 对齐技术、基础设施工艺、独家「模型沙盒」实验和现代化数据工厂,从数据、训练到调校工艺环环相扣,一条优秀的大模型Scaling Law增长曲线由此而生。
Infra工艺方面,面壁构建了全流程优化加速工具套件平台ModelForce,可以实现10倍推理加速,使得推理速度提高了10倍,同时也实现了90%的成本降低。

在算法方面,通过进行上千次以上的「模型沙盒」实验,我们致力于探索更加科学的训练模型方法。我们通过以小见大的方式,寻找高效的模型训练配置,以实现模型能力的快速形成。

➤Eurux-8x22B模型的GitHub地址:
➤Eurux-8x22B模型HuggingFace地址:[点击此处](https://huggingface.co/openbmb/Eurux-8x22b-nc)
➤UltraInterat对齐数据集地址:

