AIGC动态欢迎阅读
并行,以GPipe为例
关键字:模型,流水线,表示,大小,复杂度文章来源:智猩猩GenAI
内容字数:0字内容摘要:
回顾ChatGPT
的发展历程,我们可以总结出大语言模型(LLM)取得惊艳效果的要点(重要性从高到低排序):
愿意烧钱,且接受“烧钱 != 好模型”的现实
高质量的训练语料
高效的分布式训练框架和充沛优质的硬件资源
算法的迭代创新
在大模型训练这个系列里,我们将一起探索学习几种经典的分布式并行范式,包括流水线并行(Pipeline Parallelism),数据并行(Data Parallelism)和张量并行(Tensor Parallesim)。微软开源的分布式训练框架FastSpeed,融合了这三种并行范式,开发出3D并行的框架,实现了千亿级别模型参数的训练。
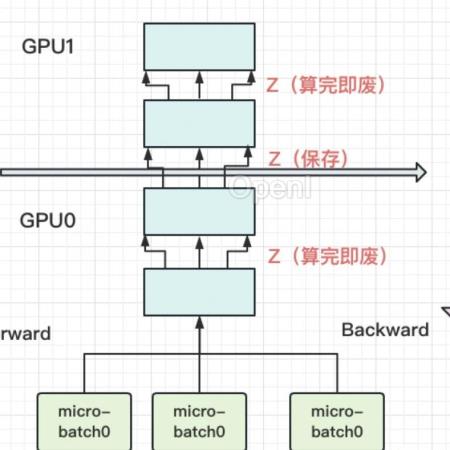
本篇文章将探索流水线并行,经典的流水线并行范式有Google推出的Gpipe,和微软推出的PipeDream。两者的推出时间都在2019年左右,大体设计框架一致。主要差别为:在梯度更新上,Gpipe是同步的,PipeDream是异步的。异步方法更进一步降低了GPU的空转时间比。虽然PipeDream设计更精妙些,但是Gpipe因为其“够用”和浅显易懂,更受大众欢迎(torch的PP接口就基于Gpipe)。因此本文以Gpipe原文链接:图解大模型训练之:流水线并行,以GPipe为例
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介: