AIGC动态欢迎阅读
原标题:大模型
智障检测+1:Strawberry有几个r纷纷数不清,最新最强Llama3.1也傻了
关键字:腾讯,报告,问题,方法,模型
文章来源:量子位
内容字数:0字内容摘要:
梦晨 一水 发自 凹非寺量子位 | 公众号 QbitAI继分不清9.11和9.9哪个大以后,大模型又“集体失智”了!
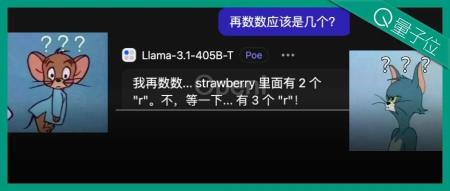
数不对单词“Strawberry”中有几个“r”,再次引起一片讨论。
GPT-4o不仅错了还很自信。
刚出炉的Llama-3.1 405B,倒是能在验证中发现问题并改正。
比较离谱的是Claude 3.5 Sonnet,还越改越错了。
说起来这并不是最新发现的问题,只是最近新模型接连发布,非常热闹。
一个个号称自己数学涨多少分,大家就再次拿出这个问题来试验,结果很是失望。
在众多相关讨论的帖子中,还翻出一条马斯克对此现象的评论:
好吧,也许AGI比我想象的还要更远。
路遇失智AI,拼尽全力终于教会有人发现,即使使用Few-Shot CoT,也就是“一步一步地想”大法附加一个人类操作示例,ChatGPT依然学不会:
倒是把r出现的位置都标成1,其他标成0,问题的难度下降了,但是数“1”依旧不擅长。
为了教会大模型数r,全球网友脑洞大开,开发出各种奇奇怪怪的提示词技巧。
比如让ChatGPT使用漫画《死亡笔记中》高智商角色“L”可能使用的方法。
ChatGPT想出的方法倒是原文链接:大模型智障检测+1:Strawberry有几个r纷纷数不清,最新最强Llama3.1也傻了
联系作者
文章来源:量子位
作者微信:
作者简介:




