AIGC动态欢迎阅读
原标题:张俊林:浅谈Llama3、大模型开源与闭源以及合成数据关键字:模型,数据,能力,侵权,知乎
文章来源:算法邦
内容字数:7021字内容摘要:
导读本文来自知乎,作者为张俊林。在本文中作者对LLAMA-3、大模型开源与闭源以及合成数据发表了一些个人看法。希望本文对大家有一定的帮助。
原文链接:https://www.zhihu.com/question/653373334
本文只做学术/技术分享,如有侵权,联系删文。LLAMA-3的发布是大模型开源届的大事,蹭下热度,在这里谈下有关LLAMA-3、大模型开源与闭源以及合成数据的一些个人看法。
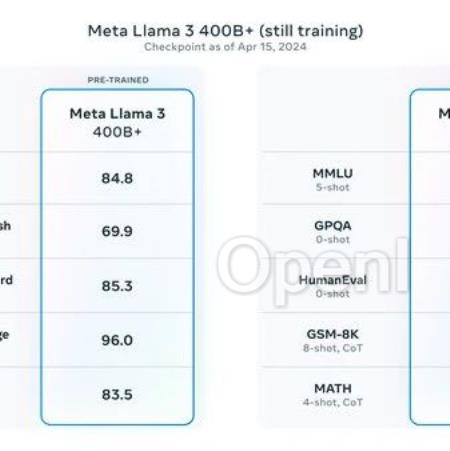
01LLAMA-3的基本情况模型结构与LLAMA-2相比没有大的变动,主要变化一点在于Token词典从LLAMA-2的32K拓展到了128K,以增加编码效率;另外一点是引入了Grouped Query Attention (GQA),这可以减少推理过程中的KV缓存大小,增加推理效率;还有一点是输入上下文长度从4K拓展到了8K,这个长度相比竞品来说仍然有点短。最重要的改变是训练数据量的极大扩充,从LLAMA-2的2T Tokens,扩展了大约8倍到了15T Tokens,其中代码数据扩充了4倍,这导致LLAMA-3在代码能力和逻辑推理能力的大幅度提升。15T token数据那是相当之大了,传原文链接:张俊林:浅谈Llama3、大模型开源与闭源以及合成数据
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,连接AI新青年,讲解研究成果,分享系统思考。




