为了方便理解,我会尽量使用非技术术语进行解释,并配上一些图表。
Transformer 是 Google Research 于 2017 年提出的一种神经网络架构,它已经被证明了在自然语言处理 (NLP) 任务中的有效性,并被广泛应用于机器翻译、文本摘要、问答等领域。
Transformer 的基本原理是通过 注意力机制 (Attention Mechanism)来学习词与词之间的依赖关系,从而更好地理解句子的语义。
以下是一张简化的 Transformer 架构图:
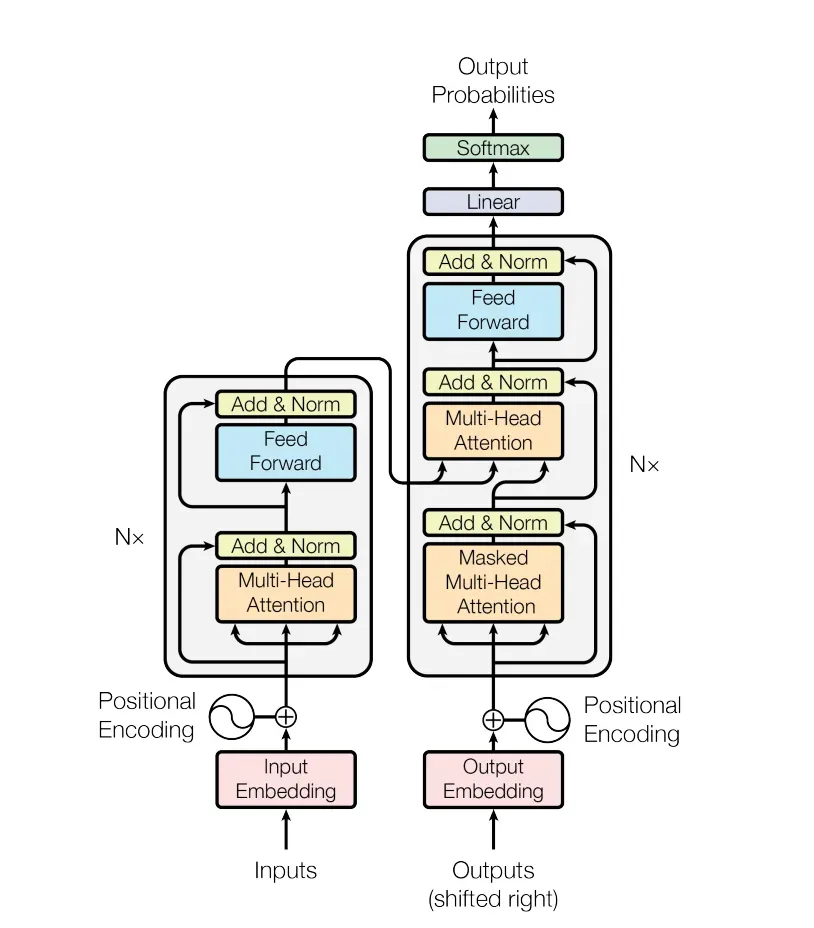
图中主要包含以下几个部分:
编码器 (Encoder): 编码器由多个相同的编码器层组成,每个编码器层又由两个子层组成: 自注意力层 (Self-Attention Layer): 自注意力层负责学习词与词之间的依赖关系。 前馈神经网络层 (Feed Forward Network Layer): 前馈神经网络层负责对每个词进行非线性变换。 解码器 (Decoder): 解码器由多个相同的解码器层组成,每个解码器层又由三个子层组成: 自注意力层 (Self-Attention Layer):解码器的自注意力层负责学习词与词之间的依赖关系,以及词与编码器输出之间的依赖关系。编码器-解码器注意力层 (Encoder-Decoder Attention Layer): 编码器-解码器注意力层负责将编码器输出的信息传递给解码器。 前馈神经网络层 (Feed Forward Network Layer): 解码器的前馈神经网络层负责对每个词进行非线性变换。 位置编码 (Positional Encoding):由于 Transformer 模型没有使用循环神经网络 (RNN),因此需要显式地将位置信息编码到输入序列中。Transformer 的工作流程如下:
将输入序列转换为词嵌入表示。 编码器对输入序列进行编码,并输出编码器输出序列。 解码器以自注意力机制为基础,根据编码器输出序列和之前生成的输出词,预测下一个词。 重复步骤 3,直到生成完整的输出序列。Transformer 的注意力机制是其核心思想,它使 Transformer 能够捕获长距离依赖关系,从而更好地理解句子的语义。
以下是一张简化的注意力机制示意图:
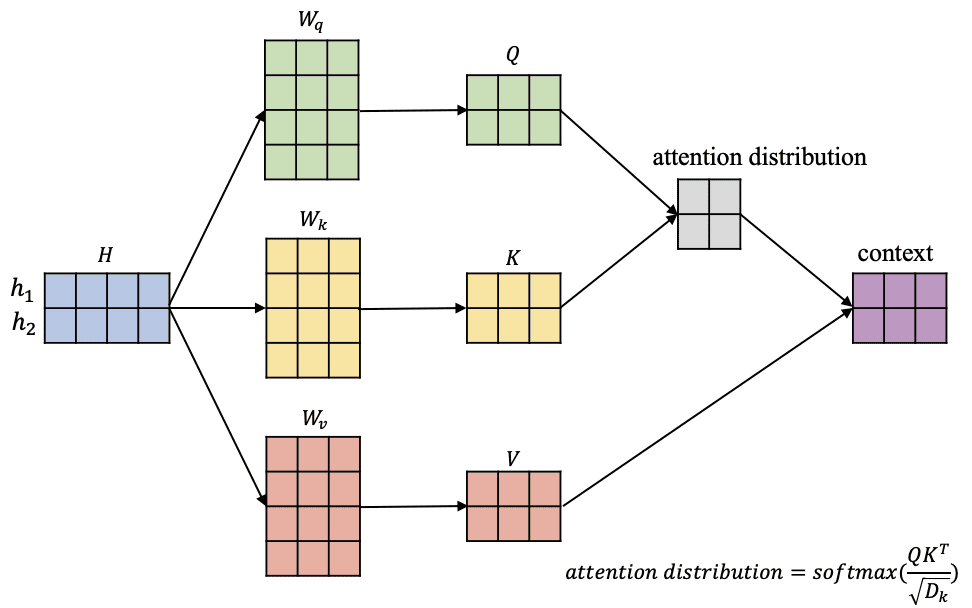
图中主要包含以下几个部分:
查询 (Query): 查询代表要计算注意力的词。 键 (Key): 键代表所有候选词。 值 (Value): 值代表所有候选词的语义信息。 注意力分数 (Attention Score): 注意力分数代表查询词与每个候选词之间的相关程度。 加权值 (Weighted Value): 加权值代表每个候选词对查询词的贡献程度。注意力机制的计算过程如下:
对查询、键和值进行缩放变换。 计算查询与每个键的点积。 对点积进行 softmax 运算,得到注意力分数。 将注意力分数与值相乘,得到加权值。 将所有加权值求和,得到最终的输出。Transformer 模型的出现是 NLP 领域的一个重大突破,它使 NLP 任务的性能得到了大幅提升。Transformer 模型及其衍生模型已经被广泛应用于各种 NLP 任务,并取得了 state-of-the-art 的结果。
希望以上解释能够帮助您理解 Transformer 的基本原理。
